
Redis
一、Redis 简介
“Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.” —— Redis是一个开放源代码(BSD许可)的内存中数据结构存储,用作数据库,缓存和消息代理。 (摘自官网)
Redis 是一个开源,高级的键值存储和一个适用的解决方案,用于构建高性能,可扩展的 Web 应用程序。Redis 也被作者戏称为 数据结构服务器 ,这意味着使用者可以通过一些命令,基于带有 TCP 套接字的简单 服务器-客户端 协议来访问一组 可变数据结构 。*(在 Redis 中都采用键值对的方式,只不过对应的数据结构不一样罢了)*
Redis 的优点
以下是 Redis 的一些优点:
- 非常快 - Redis 非常快,每秒可执行大约 110000 次的设置(SET)操作,每秒大约可执行 81000 次的读取/获取(GET)操作。
- 支持丰富的数据类型 - Redis 支持开发人员常用的大多数数据类型,例如列表,集合,排序集和散列等等。这使得 Redis 很容易被用来解决各种问题,因为我们知道哪些问题可以更好使用地哪些数据类型来处理解决。
- 操作具有原子性 - 所有 Redis 操作都是原子操作,这确保如果两个客户端并发访问,Redis 服务器能接收更新的值。
- 多实用工具 - Redis 是一个多实用工具,可用于多种用例,如:缓存,消息队列(Redis 本地支持发布/订阅),应用程序中的任何短期数据,例如,web应用程序中的会话,网页命中计数等。
Redis 的安装
这一步比较简单,你可以在网上搜到许多满意的教程,这里就不再赘述。
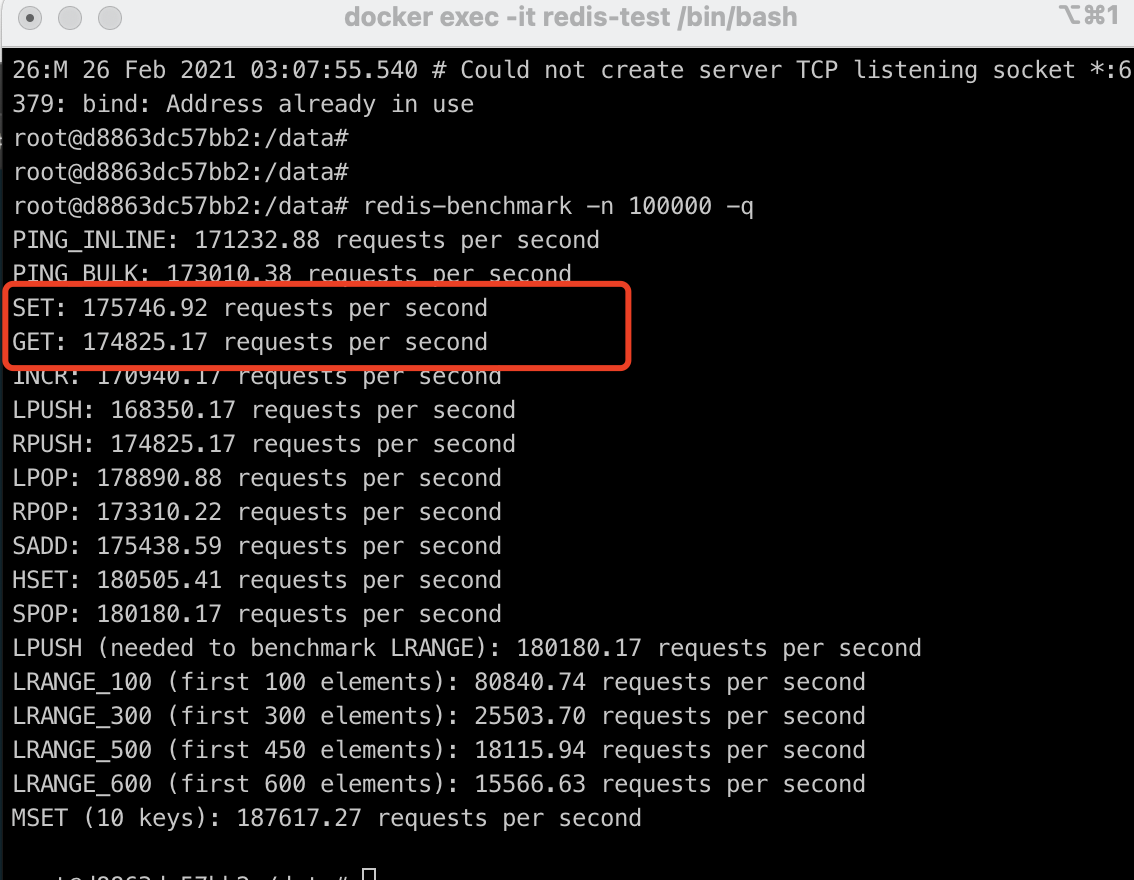
测试本地 Redis 性能
当安装完成之后,你可以先执行 redis-server 让 Redis 启动起来,然后运行命令 redis-benchmark -n 100000 -q 来检测本地同时执行 10 万个请求时的性能,以下是我在本机 docker 环境的测试结果:
二、架构实现
在目前的技术选型中,Redis 俨然已经成为了系统高性能缓存方案的事实标准,因此现在 Redis 也成为了后端开发的基本技能树之一,Redis 的底层原理也顺理成章地成为了必须学习的知识。
Redis 从本质上来讲是一个网络服务器,而对于一个网络服务器来说,网络模型是它的精华,搞懂了一个网络服务器的网络模型,你也就搞懂了它的本质。
Redis 有多快?
根据官方的 benchmark,通常来说,在一台普通硬件配置的 Linux 机器上跑单个 Redis 实例,处理简单命令(时间复杂度 O(N) 或者 O(log(N))),QPS 可以达到 8w+,而如果使用 pipeline 批处理功能,则 QPS 至高能达到 100w。
仅从性能层面进行评判,Redis 完全可以被称之为高性能缓存方案。
Redis 为什么快?
Redis 的高性能得益于以下几个基础:
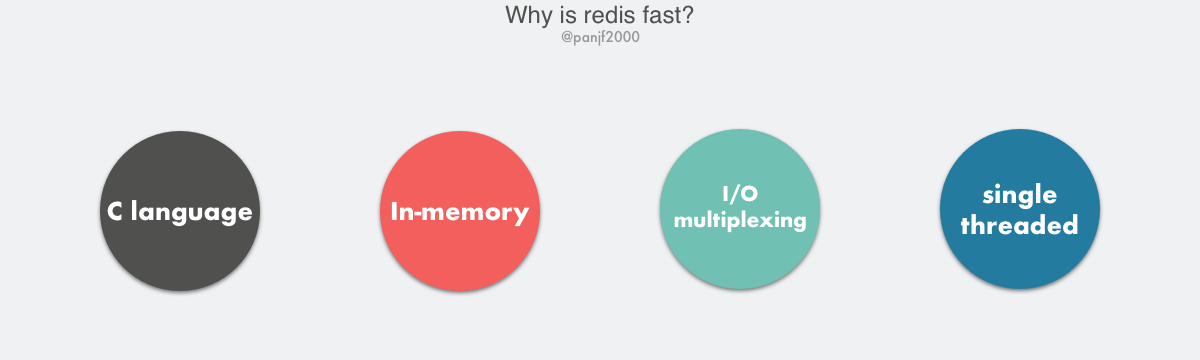
- C 语言实现,虽然 C 对 Redis 的性能有助力,但语言并不是最核心因素。
- 纯内存 I/O,相较于其他基于磁盘的 DB,Redis 的纯内存操作有着天然的性能优势。
- I/O 多路复用,基于 epoll/select/kqueue 等 I/O 多路复用技术,实现高吞吐的网络 I/O。
- 单线程模型,单线程无法利用多核,但是从另一个层面来说则避免了多线程频繁上下文切换,以及同步机制如锁带来的开销。
Redis 为何选择单线程?
Redis 的核心网络模型选择用单线程来实现,这在一开始就引起了很多人的不解,Redis 官方的对于此的回答是:
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
核心意思就是,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 选择了单线程的 I/O 多路复用来实现它的核心网络模型。
上面是比较笼统的官方答案,实际上更加具体的选择单线程的原因可以归纳如下:
避免过多的上下文切换开销
多线程调度过程中必然需要在 CPU 之间切换线程上下文 context,而上下文的切换又涉及程序计数器、堆栈指针和程序状态字等一系列的寄存器置换、程序堆栈重置甚至是 CPU 高速缓存、TLB 快表的汰换,如果是进程内的多线程切换还好一些,因为单一进程内多线程共享进程地址空间,因此线程上下文比之进程上下文要小得多,如果是跨进程调度,则需要切换掉整个进程地址空间。
如果是单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景。
避免同步机制的开销
如果 Redis 选择多线程模型,又因为 Redis 是一个数据库,那么势必涉及到底层数据同步的问题,则必然会引入某些同步机制,比如锁,而我们知道 Redis 不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能。
简单可维护
Redis 的作者 Salvatore Sanfilippo (别称 antirez) 对 Redis 的设计和代码有着近乎偏执的简洁性理念,你可以在阅读 Redis 的源码或者给 Redis 提交 PR 的之时感受到这份偏执。因此代码的简单可维护性必然是 Redis 早期的核心准则之一,而引入多线程必然会导致代码的复杂度上升和可维护性下降。
事实上,多线程编程也不是那么尽善尽美,首先多线程的引入会使得程序不再保持代码逻辑上的串行性,代码执行的顺序将变成不可预测的,稍不注意就会导致程序出现各种并发编程的问题;其次,多线程模式也使得程序调试更加复杂和麻烦。网络上有一幅很有意思的图片,生动形象地描述了并发编程面临的窘境。
你期望的多线程编程 VS 实际上的多线程编程:

Redis 真的是单线程?
在讨论这个问题之前,我们要先明确『单线程』这个概念的边界:它的覆盖范围是核心网络模型,抑或是整个 Redis?如果是前者,那么答案是肯定的,在 Redis 的 v6.0 版本正式引入多线程之前,其网络模型一直是单线程模式的;如果是后者,那么答案则是否定的,Redis 早在 v4.0 就已经引入了多线程。
因此,当我们讨论 Redis 的多线程之时,有必要对 Redis 的版本划出两个重要的节点:
- Redis v4.0(引入多线程处理异步任务)
- Redis v6.0(正式在网络模型中实现 I/O 多线程)
单线程事件循环
我们首先来剖析一下 Redis 的核心网络模型,从 Redis 的 v1.0 到 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型:利用 epoll/select/kqueue 等多路复用技术,在单线程的事件循环中不断去处理事件(客户端请求),最后回写响应数据到客户端:
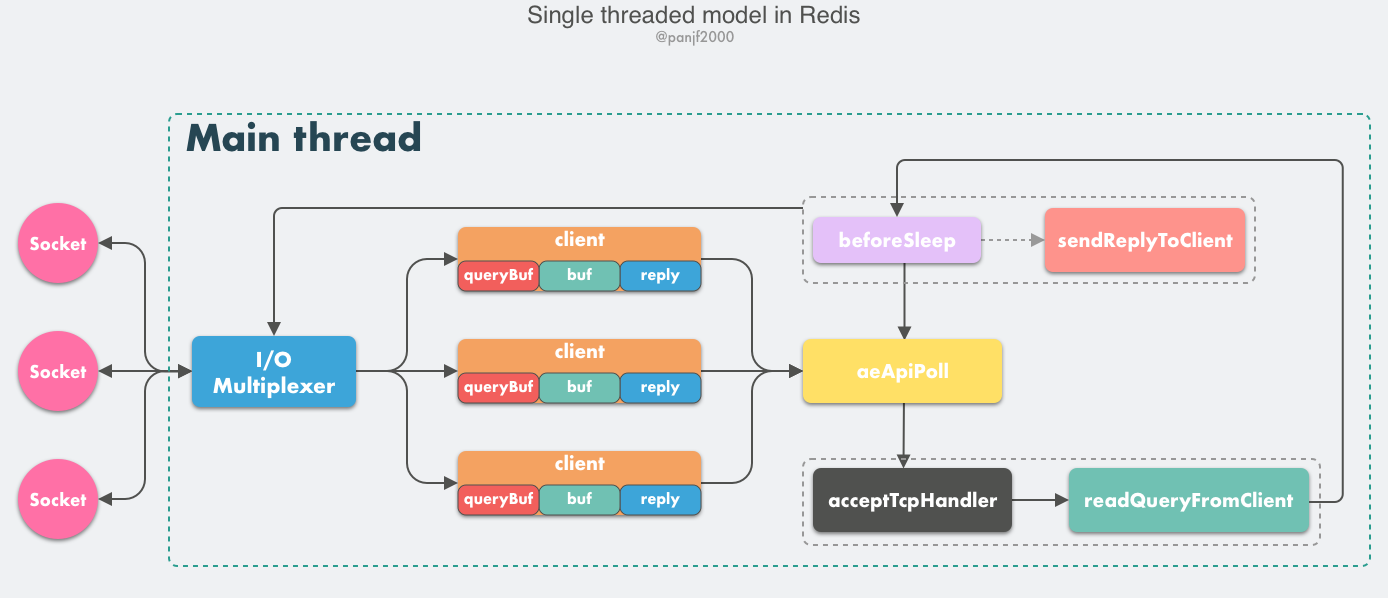
这里有几个核心的概念需要学习:
- client:客户端对象,Redis 是典型的 CS 架构(Client <—> Server),客户端通过 socket 与服务端建立网络通道然后发送请求命令,服务端执行请求的命令并回复。Redis 使用结构体 client 存储客户端的所有相关信息,包括但不限于
封装的套接字连接 -- *conn,当前选择的数据库指针 -- *db,读入缓冲区 -- querybuf,写出缓冲区 -- buf,写出数据链表 -- reply等。 - aeApiPoll:I/O 多路复用 API,是基于 epoll_wait/select/kevent 等系统调用的封装,监听等待读写事件触发,然后处理,它是事件循环(Event Loop)中的核心函数,是事件驱动得以运行的基础。
- acceptTcpHandler:连接应答处理器,底层使用系统调用
accept接受来自客户端的新连接,并为新连接注册绑定命令读取处理器,以备后续处理新的客户端 TCP 连接;除了这个处理器,还有对应的acceptUnixHandler负责处理 Unix Domain Socket 以及acceptTLSHandler负责处理 TLS 加密连接。 - readQueryFromClient:命令读取处理器,解析并执行客户端的请求命令。
- beforeSleep:事件循环中进入 aeApiPoll 等待事件到来之前会执行的函数,其中包含一些日常的任务,比如把
client->buf或者client->reply(后面会解释为什么这里需要两个缓冲区)中的响应写回到客户端,持久化 AOF 缓冲区的数据到磁盘等,相对应的还有一个 afterSleep 函数,在 aeApiPoll 之后执行。 - sendReplyToClient:命令回复处理器,当一次事件循环之后写出缓冲区中还有数据残留,则这个处理器会被注册绑定到相应的连接上,等连接触发写就绪事件时,它会将写出缓冲区剩余的数据回写到客户端。
Redis 内部实现了一个高性能的事件库 — AE,基于 epoll/select/kqueue/evport 四种事件驱动技术,实现 Linux/MacOS/FreeBSD/Solaris 多平台的高性能事件循环模型。Redis 的核心网络模型正式构筑在 AE 之上,包括 I/O 多路复用、各类处理器的注册绑定,都是基于此才得以运行。
至此,我们可以描绘出客户端向 Redis 发起请求命令的工作原理:
- Redis 服务器启动,开启主线程事件循环(Event Loop),注册
acceptTcpHandler连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来; - 客户端和服务端建立网络连接;
acceptTcpHandler被调用,主线程使用 AE 的 API 将readQueryFromClient命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个client绑定这个客户端连接;- 客户端发送请求命令,触发读就绪事件,主线程调用
readQueryFromClient通过 socket 读取客户端发送过来的命令存入client->querybuf读入缓冲区; - 接着调用
processInputBuffer,在其中使用processInlineBuffer或者processMultibulkBuffer根据 Redis 协议解析命令,最后调用processCommand执行命令; - 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用
addReply函数族的一系列函数将响应数据写入到对应client的写出缓冲区:client->buf或者client->reply,client->buf是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到client->reply链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把client添加进一个 LIFO 队列clients_pending_write; - 在事件循环(Event Loop)中,主线程执行
beforeSleep–>handleClientsWithPendingWrites,遍历clients_pending_write队列,调用writeToClient把client的写出缓冲区里的数据回写到客户端,如果写出缓冲区还有数据遗留,则注册sendReplyToClient命令回复处理器到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据。
对于那些想利用多核优势提升性能的用户来说,Redis 官方给出的解决方案也非常简单粗暴:在同一个机器上多跑几个 Redis 实例。事实上,为了保证高可用,线上业务一般不太可能会是单机模式,更加常见的是利用 Redis 分布式集群多节点和数据分片负载均衡来提升性能和保证高可用。
多线程异步任务
以上便是 Redis 的核心网络模型,这个单线程网络模型一直到 Redis v6.0 才改造成多线程模式,但这并不意味着整个 Redis 一直都只是单线程。
Redis 在 v4.0 版本的时候就已经引入了的多线程来做一些异步操作,此举主要针对的是那些非常耗时的命令,通过将这些命令的执行进行异步化,避免阻塞单线程的事件循环。
我们知道 Redis 的 DEL 命令是用来删除掉一个或多个 key 储存的值,它是一个阻塞的命令,大多数情况下你要删除的 key 里存的值不会特别多,最多也就几十上百个对象,所以可以很快执行完,但是如果你要删的是一个超大的键值对,里面有几百万个对象,那么这条命令可能会阻塞至少好几秒,又因为事件循环是单线程的,所以会阻塞后面的其他事件,导致吞吐量下降。
Redis 的作者 antirez 为了解决这个问题进行了很多思考,一开始他想的办法是一种渐进式的方案:利用定时器和数据游标,每次只删除一小部分的数据,比如 1000 个对象,最终清除掉所有的数据,但是这种方案有个致命的缺陷,如果同时还有其他客户端往某个正在被渐进式删除的 key 里继续写入数据,而且删除的速度跟不上写入的数据,那么将会无止境地消耗内存,虽然后来通过一个巧妙的办法解决了,但是这种实现使 Redis 变得更加复杂,而多线程看起来似乎是一个水到渠成的解决方案:简单、易理解。于是,最终 antirez 选择引入多线程来实现这一类非阻塞的命令。更多 antirez 在这方面的思考可以阅读一下他发表的博客:Lazy Redis is better Redis。
于是,在 Redis v4.0 之后增加了一些的非阻塞命令如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC。
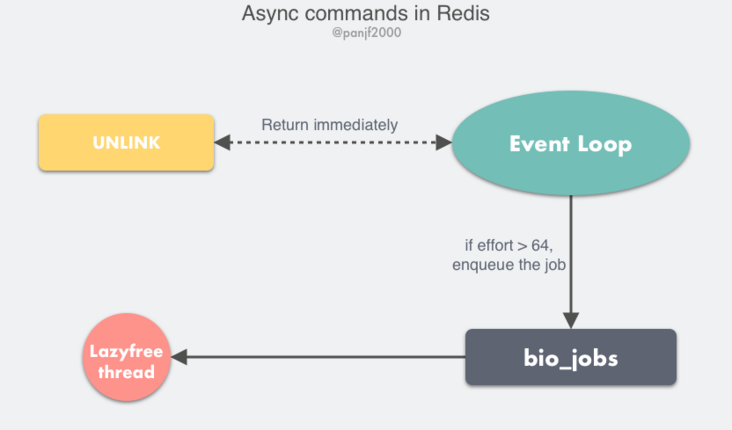
UNLINK 命令其实就是 DEL 的异步版本,它不会同步删除数据,而只是把 key 从 keyspace 中暂时移除掉,然后将任务添加到一个异步队列,最后由后台线程去删除,不过这里需要考虑一种情况是如果用 UNLINK 去删除一个很小的 key,用异步的方式去做反而开销更大,所以它会先计算一个开销的阀值,只有当这个值大于 64 才会使用异步的方式去删除 key,对于基本的数据类型如 List、Set、Hash 这些,阀值就是其中存储的对象数量。
Redis 多线程网络模型
前面提到 Redis 最初选择单线程网络模型的理由是:CPU 通常不会成为性能瓶颈,瓶颈往往是内存和网络,因此单线程足够了。那么为什么现在 Redis 又要引入多线程呢?很简单,就是 Redis 的网络 I/O 瓶颈已经越来越明显了。
随着互联网的飞速发展,互联网业务系统所要处理的线上流量越来越大,Redis 的单线程模式会导致系统消耗很多 CPU 时间在网络 I/O 上从而降低吞吐量,要提升 Redis 的性能有两个方向:
- 优化网络 I/O 模块
- 提高机器内存读写的速度
后者依赖于硬件的发展,暂时无解。所以只能从前者下手,网络 I/O 的优化又可以分为两个方向:
- 零拷贝技术或者 DPDK 技术
- 利用多核优势
零拷贝技术有其局限性,无法完全适配 Redis 这一类复杂的网络 I/O 场景,更多网络 I/O 对 CPU 时间的消耗和 Linux 零拷贝技术,可以阅读另一篇文章:Linux I/O 原理和 Zero-copy 技术全面揭秘。而 DPDK 技术通过旁路网卡 I/O 绕过内核协议栈的方式又太过于复杂以及需要内核甚至是硬件的支持。
因此,利用多核优势成为了优化网络 I/O 性价比最高的方案。
6.0 版本之后,Redis 正式在核心网络模型中引入了多线程,也就是所谓的 I/O threading,至此 Redis 真正拥有了多线程模型。前一小节,我们了解了 Redis 在 6.0 版本之前的单线程事件循环模型,实际上就是一个非常经典的 Reactor 模型:
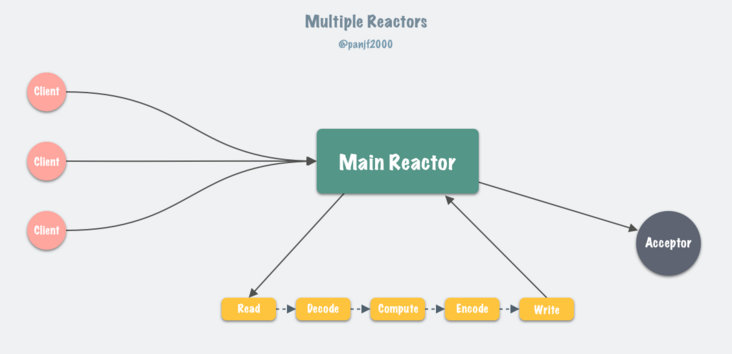
目前 Linux 平台上主流的高性能网络库/框架中,大都采用 Reactor 模式,比如 netty、libevent、libuv、POE(Perl)、Twisted(Python)等。
Reactor 模式本质上指的是使用 I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O) 的模式。
更多关于 Reactor 模式的细节可以参考文章:Go netpoller 原生网络模型之源码全面揭秘,Reactor 网络模型那一小节,这里不再赘述。
Redis 的核心网络模型在 6.0 版本之前,一直是单 Reactor 模式:所有事件的处理都在单个线程内完成,虽然在 4.0 版本中引入了多线程,但是那个更像是针对特定场景(删除超大 key 值等)而打的补丁,并不能被视作核心网络模型的多线程。
通常来说,单 Reactor 模式,引入多线程之后会进化为 Multi-Reactors 模式,基本工作模式如下
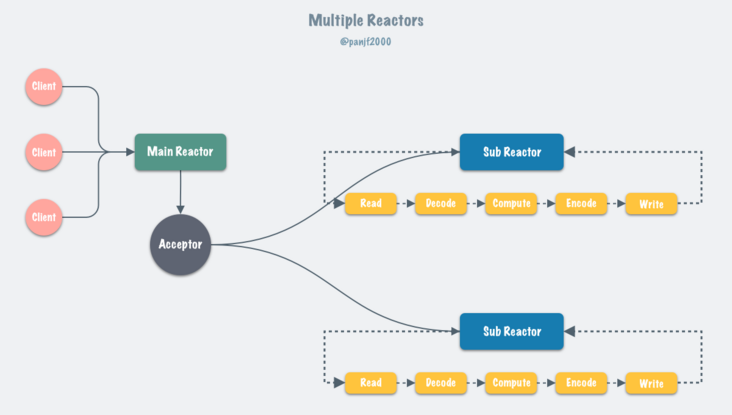
区别于单 Reactor 模式,这种模式不再是单线程的事件循环,而是有多个线程(Sub Reactors)各自维护一个独立的事件循环,由 Main Reactor 负责接收新连接并分发给 Sub Reactors 去独立处理,最后 Sub Reactors 回写响应给客户端。
Multiple Reactors 模式通常也可以等同于 Master-Workers 模式,比如 Nginx 和 Memcached 等就是采用这种多线程模型,虽然不同的项目实现细节略有区别,但总体来说模式是一致的。
设计思路
Redis 虽然也实现了多线程,但是却不是标准的 Multi-Reactors/Master-Workers 模式,这其中的缘由我们后面会分析,现在我们先看一下 Redis 多线程网络模型的总体设计
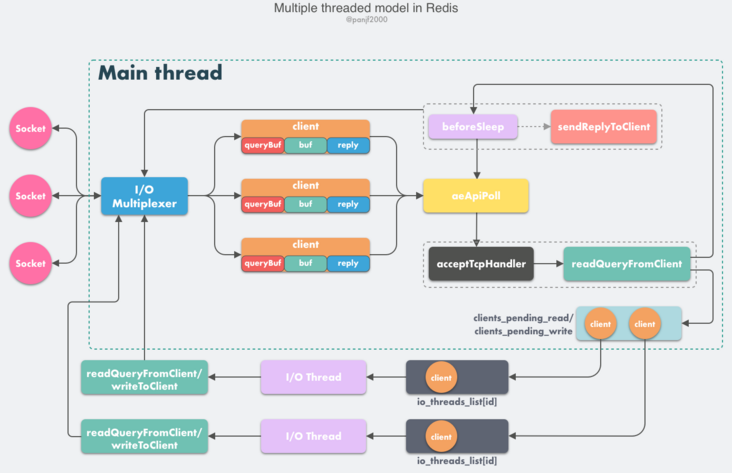
- Redis 服务器启动,开启主线程事件循环(Event Loop),注册
acceptTcpHandler连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来; - 客户端和服务端建立网络连接;
acceptTcpHandler被调用,主线程使用 AE 的 API 将readQueryFromClient命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个client绑定这个客户端连接;- 客户端发送请求命令,触发读就绪事件,服务端主线程不会通过 socket 去读取客户端的请求命令,而是先将
client放入一个 LIFO 队列clients_pending_read; - 在事件循环(Event Loop)中,主线程执行
beforeSleep–>handleClientsWithPendingReadsUsingThreads,利用 Round-Robin 轮询负载均衡策略,把clients_pending_read队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列io_threads_list[id]和主线程自己,I/O 线程通过 socket 读取客户端的请求命令,存入client->querybuf并解析第一个命令,但不执行命令,主线程忙轮询,等待所有 I/O 线程完成读取任务; - 主线程和所有 I/O 线程都完成了读取任务,主线程结束忙轮询,遍历
clients_pending_read队列,执行所有客户端连接的请求命令,先调用processCommandAndResetClient执行第一条已经解析好的命令,然后调用processInputBuffer解析并执行客户端连接的所有命令,在其中使用processInlineBuffer或者processMultibulkBuffer根据 Redis 协议解析命令,最后调用processCommand执行命令; - 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用
addReply函数族的一系列函数将响应数据写入到对应client的写出缓冲区:client->buf或者client->reply,client->buf是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到client->reply链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把client添加进一个 LIFO 队列clients_pending_write; - 在事件循环(Event Loop)中,主线程执行
beforeSleep–>handleClientsWithPendingWritesUsingThreads,利用 Round-Robin 轮询负载均衡策略,把clients_pending_write队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列io_threads_list[id]和主线程自己,I/O 线程通过调用writeToClient把client的写出缓冲区里的数据回写到客户端,主线程忙轮询,等待所有 I/O 线程完成写出任务; - 主线程和所有 I/O 线程都完成了写出任务, 主线程结束忙轮询,遍历
clients_pending_write队列,如果client的写出缓冲区还有数据遗留,则注册sendReplyToClient到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据。
这里大部分逻辑和之前的单线程模型是一致的,变动的地方仅仅是把读取客户端请求命令和回写响应数据的逻辑异步化了,交给 I/O 线程去完成,这里需要特别注意的一点是:I/O 线程仅仅是读取和解析客户端命令而不会真正去执行命令,客户端命令的执行最终还是要在主线程上完成。
性能提升
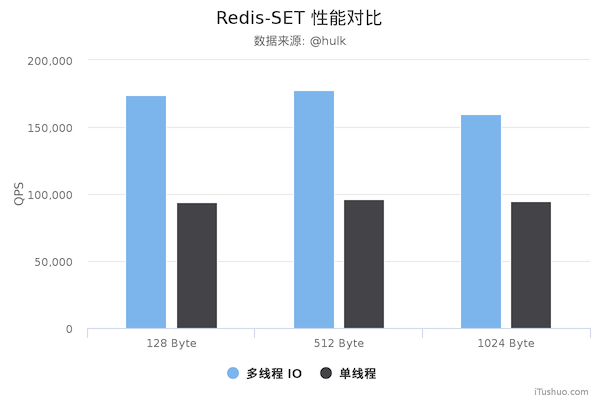
Redis 将核心网络模型改造成多线程模式追求的当然是最终性能上的提升,所以最终还是要以 benchmark 数据见真章:
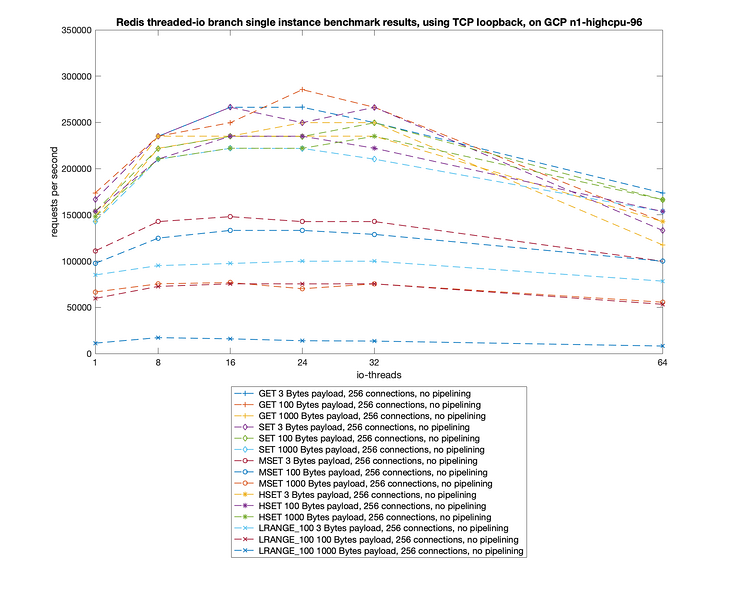
测试数据表明,Redis 在使用多线程模式之后性能大幅提升,达到了一倍。更详细的性能压测数据可以参阅这篇文章:Benchmarking the experimental Redis Multi-Threaded I/O。
以下是美图技术团队实测的新旧 Redis 版本性能对比图,仅供参考:
三、Redis 五种基本数据结构
Redis 有 5 种基础数据结构,它们分别是:string(字符串)、list(列表)、hash(字典)、set(集合) 和 **zset(有序集合)**。这 5 种是 Redis 相关知识中最基础、最重要的部分。
字符串 string
Redis 中的字符串是一种 动态字符串,这意味着使用者可以修改,它的底层实现有点类似于 Java 中的 ArrayList,有一个字符数组,从源码的 sds.h/sdshdr 文件 中可以看到 Redis 底层对于字符串的定义 SDS,即 Simple Dynamic String 结构:
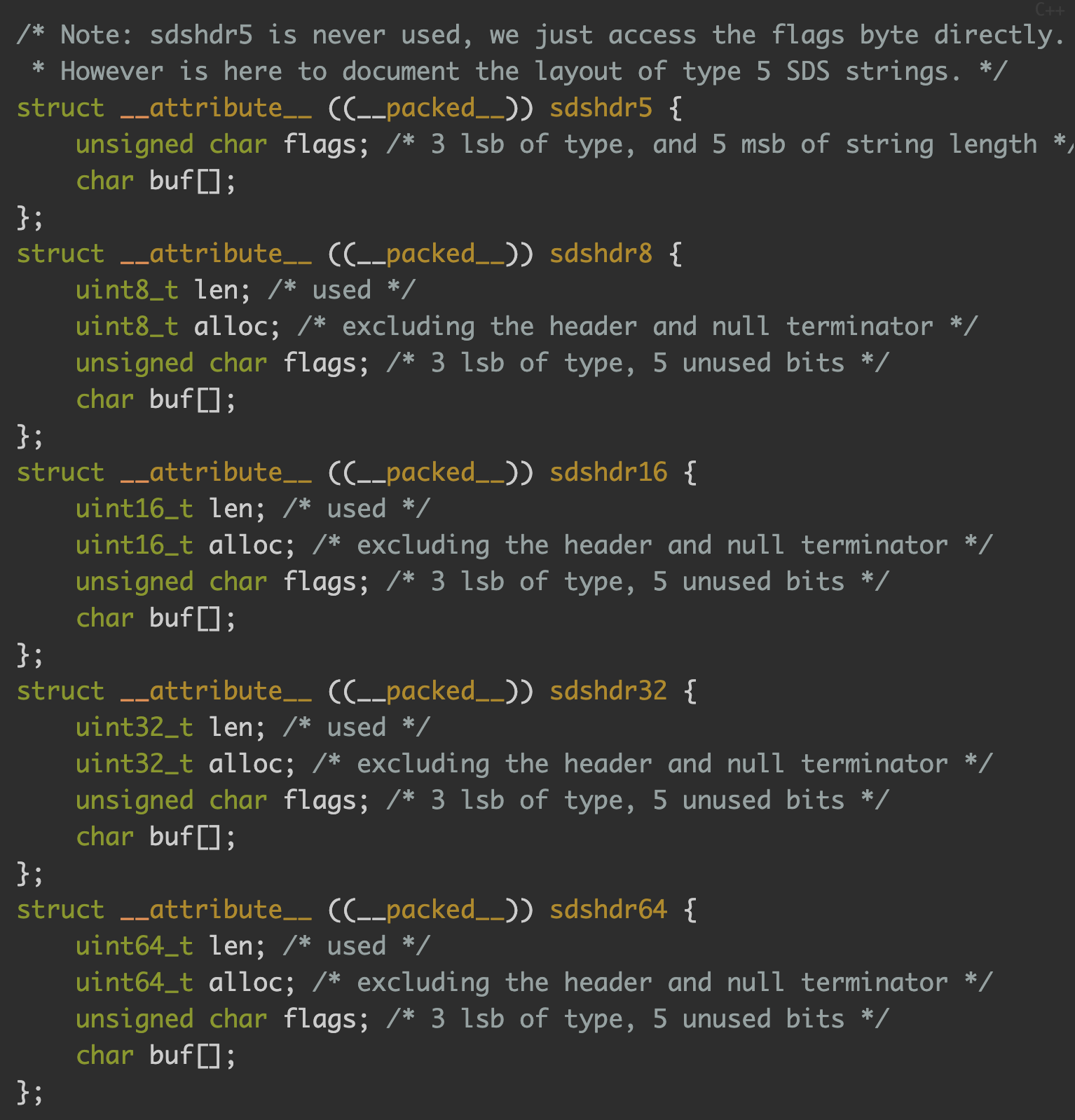
- Redis 没有直接使用 C 语言的字符串,而是构建了自己的抽象类型简单动态字符串(simple dynamic string)。
在 Redis 中,对于所有键,都是字符串类型,其底层实现是 SDS,而键值对的值,其实最终都是以字符串为粒度的,底层都是 SDS 实现。(比如列表,其实列表中每一项都是字符串以 SDS 实现的)。
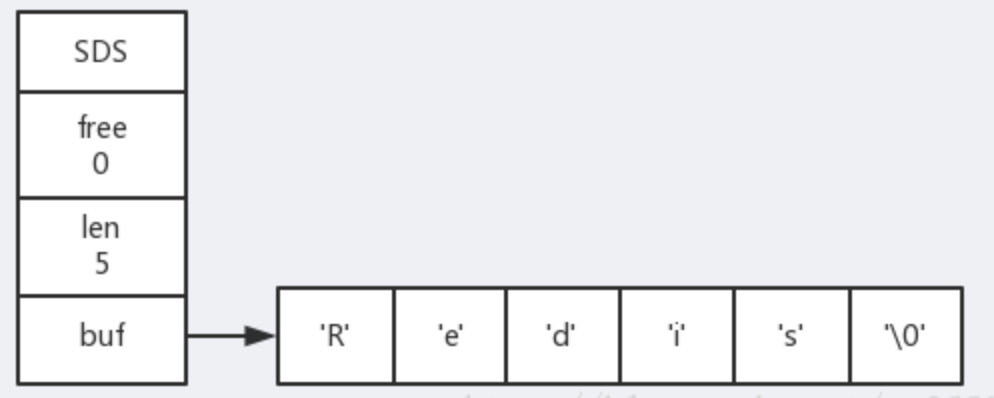
- SDS 结构中,包含 char 类型的数组 buf ,每个位置存储字符,最后一个位置存储空字符 ‘\0’。另外,还有 free 属性和 len 属性。free 属性的值代表未使用空间的大小,len 属性代表目前保存的字符串的实际长度,结尾的 ‘\0’ 空字符不计算在内。
- SDS 的优势:
- C 语言的字符串不会记录自己的长度,而是需要进行遍历获得,时间复杂度为 O(n) ,而 SDS 已经封装了 len 属性,直接读取 len 的值就可以获得长度,不需要遍历,时间复杂度 O(1) 。
- C 语言字符串修改时,有可能发生缓冲区溢出;而 SDS 要修改时,API 会先检查 SDS 的空间是否满足修改的要求,如果不满足,会将 SDS 的空间扩展至执行修改的所需的大小,然后才执行实际的修改操作。
SDS 的优化策略
空间预分配
空间预分配,用于优化 SDS 的字符串增长操作,当 SDS 的 API 对一个 SDS 进行修改,并且需要对 SDS 进行空间扩展的时候,程序不仅会为 SDS 分配修改所必须要的空间,还会为 SDS 分配额外的未使用空间。(这个有点类似于 Java 中的 ArrayList 的空间每次增长扩大为之前 1.5 倍大小,进行额外的空间预分配)。
具体的分配规则:- 如果修改后的 SDS 长度 len 小于 1MB,那么程序分配和 len 属性相等的未使用空间,此时 free 和 len 的值相同。所以此时数组的实际长度为 free + len + 1byte(额外的空字符 1 个字节)。
- 如果修改后的 SDS 长度大于 1MB,那么程序分配 1MB 的未使用空间。实际长度为 len + 1MB + 1byte。
在扩展 SDS 之前,会检查未使用空间是否够用,如果足够,就不用内存重分配,直接使用剩余空间即可。
惰性空间释放
惰性空间释放,用于优化 SDS 的字符串缩短操作,当 SDS 的 API 对一个 SDS 进行缩短时,并不会立即使用内存重分配来回收多出来的字节,而是使用 free 属性将这些字节的数量记录下来,等待将来使用。
通过此策略,可以避免内存重分配,同时将来增长操作也有空间。
同时 SDS 也有相应的 API ,用来真正释放未使用空间,不用担心内存的浪费。二进制存储
在 C 语言字符串中,’\0’ 空字符会被认为是字符串的结束,如果二进制数据中有该字符的存在,会被认为是字符串的结尾。而 SDS 由于有 len 属性的存在,使用 len 来判断字符串是否结束,而不是空字符。这样就避免了二进制数据的问题,可以用来保存图片,音频,视频等文件的二进制数据。
对字符串的基本操作
安装好 Redis,我们可以使用 redis-cli 来对 Redis 进行命令行的操作,当然 Redis 官方也提供了在线的调试器,你也可以在里面敲入命令进行操作:http://try.redis.io/#run
设置和获取键值对
1 | SET key value |
正如你看到的,我们通常使用 SET 和 GET 来设置和获取字符串值。
值可以是任何种类的字符串(包括二进制数据),例如你可以在一个键下保存一张 .jpeg 图片,只需要注意不要超过 512 MB 的最大限度就好了。
当 key 存在时,SET 命令会覆盖掉你上一次设置的值:
1 | SET key newValue |
另外你还可以使用 EXISTS 和 DEL 关键字来查询是否存在和删除键值对:
1 | EXISTS key |
批量设置键值对
1 | SET key1 value1 |
过期和 SET 命令扩展
可以对 key 设置过期时间,到时间会被自动删除,这个功能常用来控制缓存的失效时间。*(过期可以是任意数据结构)*
1 | SET key value1 |
等价于 SET + EXPIRE 的 SETEX 命令:
1 | SETEX key value1 |
计数
如果 value 是一个整数,还可以对它使用 INCR 命令进行 原子性 的自增操作,这意味着及时多个客户端对同一个 key 进行操作,也决不会导致竞争的情况:
1 | SET counter 100 |
返回原值的 GETSET 命令
对字符串,还有一个 GETSET 比较让人觉得有意思,它的功能跟它名字一样:为 key 设置一个值并返回原值:
1 | SET key value |
这可以对于某一些需要隔一段时间就统计的 key 很方便的设置和查看,例如:系统每当由用户进入的时候你就是用 INCR 命令操作一个 key,当需要统计时候你就把这个 key 使用 GETSET 命令重新赋值为 0,这样就达到了统计的目的。
列表 list
Redis 的列表相当于 Java 语言中的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
我们可以从源码的 adlist.h/listNode 来看到对其的定义:
1 | COPY/* Node, List, and Iterator are the only data structures used currently. */ |
可以看到,多个 listNode 可以通过 prev 和 next 指针组成双向链表:

虽然仅仅使用多个 listNode 结构就可以组成链表,但是使用 adlist.h/list 结构来持有链表的话,操作起来会更加方便:

链表的基本操作
LPUSH和RPUSH分别可以向 list 的左边(头部)和右边(尾部)添加一个新元素;LRANGE命令可以从 list 中取出一定范围的元素;LINDEX命令可以从 list 中取出指定下表的元素,相当于 Java 链表操作中的get(int index)操作;
示范:
1 | rpush mylist A |
list 实现队列
队列是先进先出的数据结构,常用于消息排队和异步逻辑处理,它会确保元素的访问顺序:
1 | RPUSH books python java golang |
list 实现栈
栈是先进后出的数据结构,跟队列正好相反:
1 | RPUSH books python java golang |
字典 hash
Redis 中的字典相当于 Java 中的 HashMap,内部实现也差不多类似,都是通过 “数组 + 链表” 的链地址法来解决部分 哈希冲突,同时这样的结构也吸收了两种不同数据结构的优点。源码定义如 dict.h/dictht 定义:
1 | COPYtypedef struct dictht { |
table 属性是一个数组,数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针,而每个 dictEntry 结构保存着一个键值对:
1 | COPYtypedef struct dictEntry { |
可以从上面的源码中看到,实际上字典结构的内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的,但是在字典扩容缩容时,需要分配新的 hashtable,然后进行 渐进式搬迁 *(下面说原因)*。
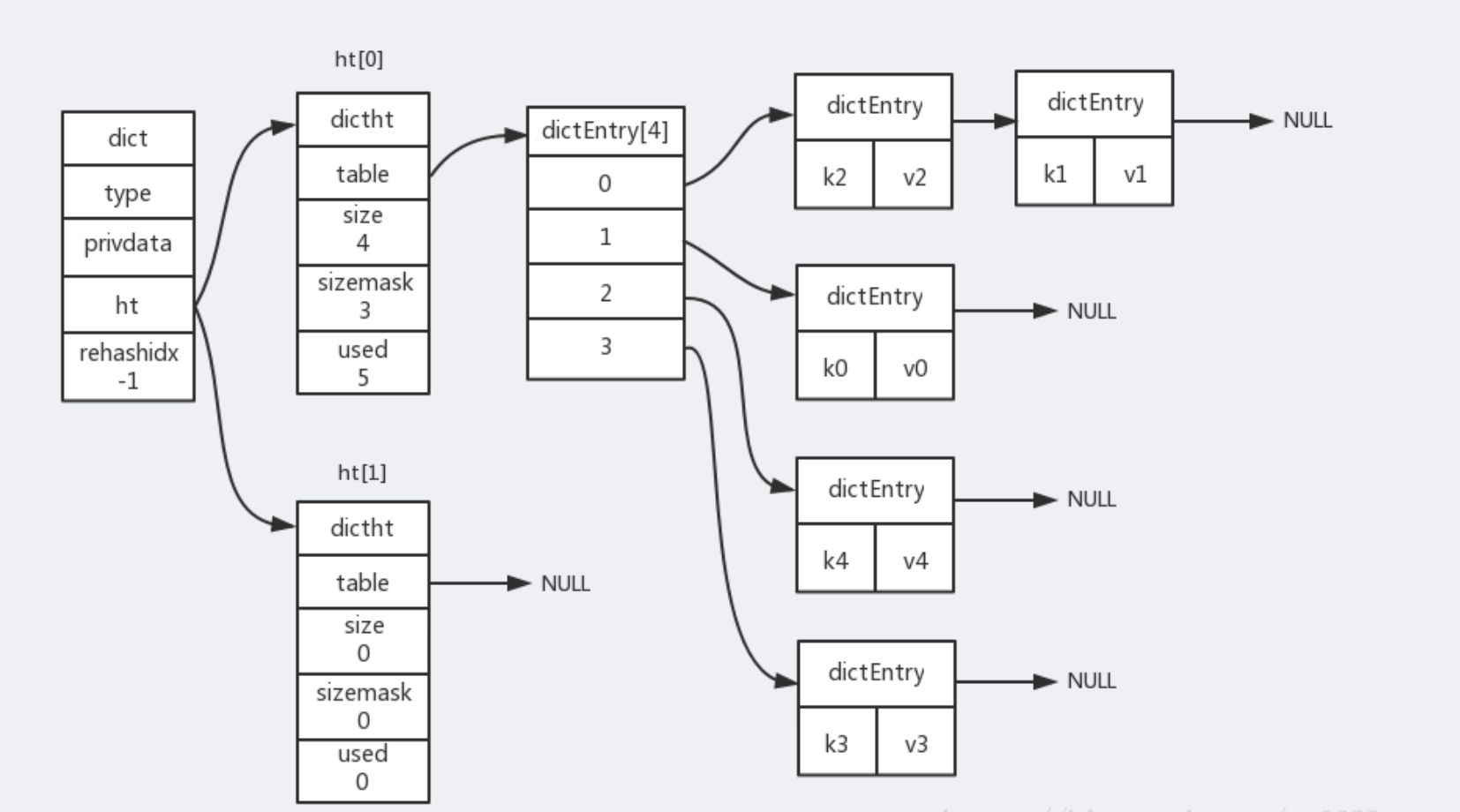
渐进式 rehash
大字典的扩容是比较耗时间的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个 O(n) 级别的操作,作为单线程的 Redis 很难承受这样耗时的过程,所以 Redis 使用 渐进式 rehash 小步搬迁:
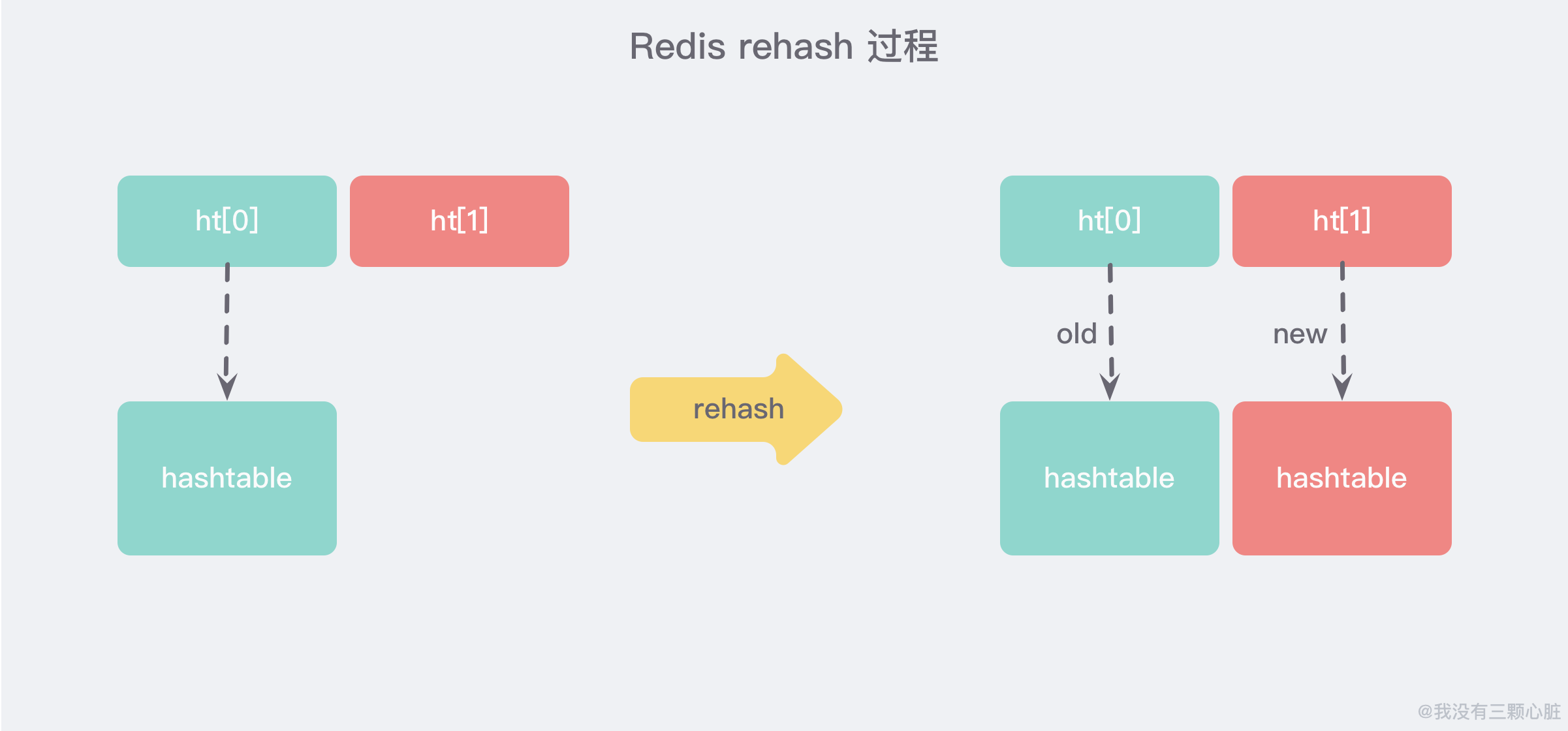
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,如上图所示,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进的把旧字典的内容迁移到新字典中。当搬迁完成了,就会使用新的 hash 结构取而代之。
扩缩容的条件
正常情况下,当 hash 表中 元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是 原数组大小的 2 倍。不过如果 Redis 正在做 bgsave(持久化命令),为了减少内存也得过多分离,Redis 尽量不去扩容,但是如果 hash 表非常满了,达到了第一维数组长度的 5 倍了,这个时候就会 强制扩容。
当 hash 表因为元素逐渐被删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。所用的条件是 **元素个数低于数组长度的 10%**,缩容不会考虑 Redis 是否在做 bgsave。
字典的基本操作
hash 也有缺点,hash 结构的存储消耗要高于单个字符串,所以到底该使用 hash 还是字符串,需要根据实际情况再三权衡:
1 | HSET books java "think in java" # 命令行的字符串如果包含空格则需要使用引号包裹 |
集合 set
Redis 的集合相当于 Java 语言中的 HashSet,它内部的键值对是无序、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
集合 set 的基本使用
由于该结构比较简单,我们直接来看看是如何使用的:
1 | SADD books java |
有序列表 zset
这可能使 Redis 最具特色的一个数据结构了,它类似于 Java 中 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以为每个 value 赋予一个 score 值,用来代表排序的权重。
它的内部实现用的是一种叫做 「跳跃表」 的数据结构,由于比较复杂,所以在这里简单提一下原理就好了:

想象你是一家创业公司的老板,刚开始只有几个人,大家都平起平坐。后来随着公司的发展,人数越来越多,团队沟通成本逐渐增加,渐渐地引入了组长制,对团队进行划分,于是有一些人又是员工又有组长的身份。
再后来,公司规模进一步扩大,公司需要再进入一个层级:部门。于是每个部门又会从组长中推举一位选出部长。
跳跃表就类似于这样的机制,最下面一层所有的元素都会串起来,都是员工,然后每隔几个元素就会挑选出一个代表,再把这几个代表使用另外一级指针串起来。然后再在这些代表里面挑出二级代表,再串起来。最终形成了一个金字塔的结构。
想一下你目前所在的地理位置:亚洲 > 中国 > 某省 > 某市 > ….,就是这样一个结构!
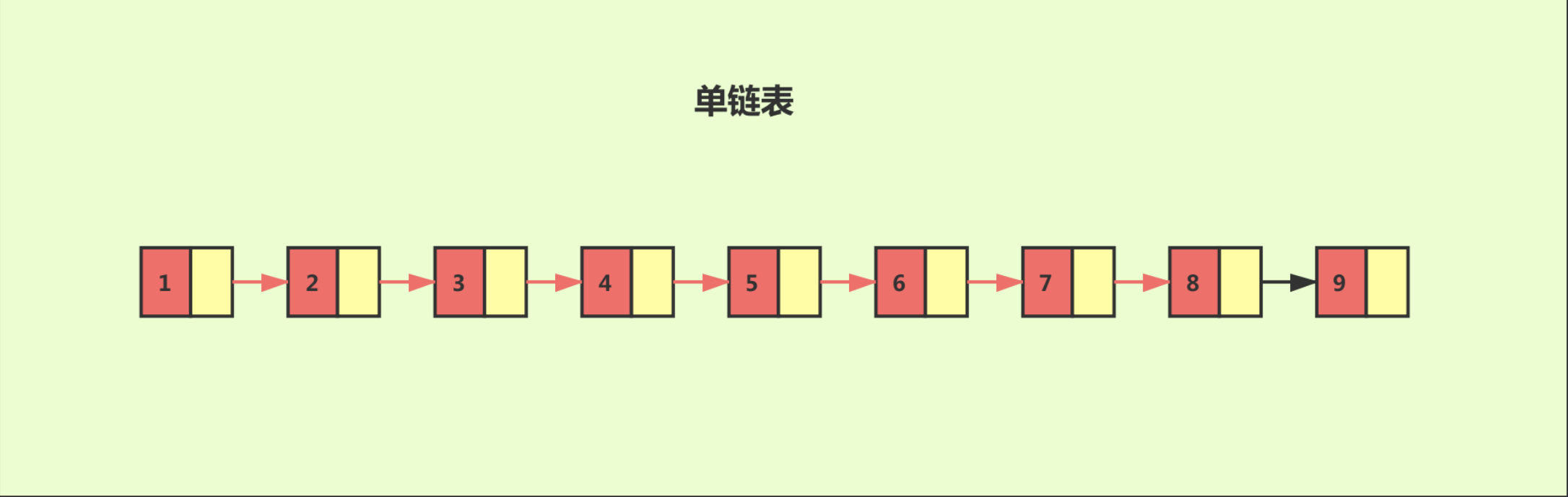
跳跃表
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
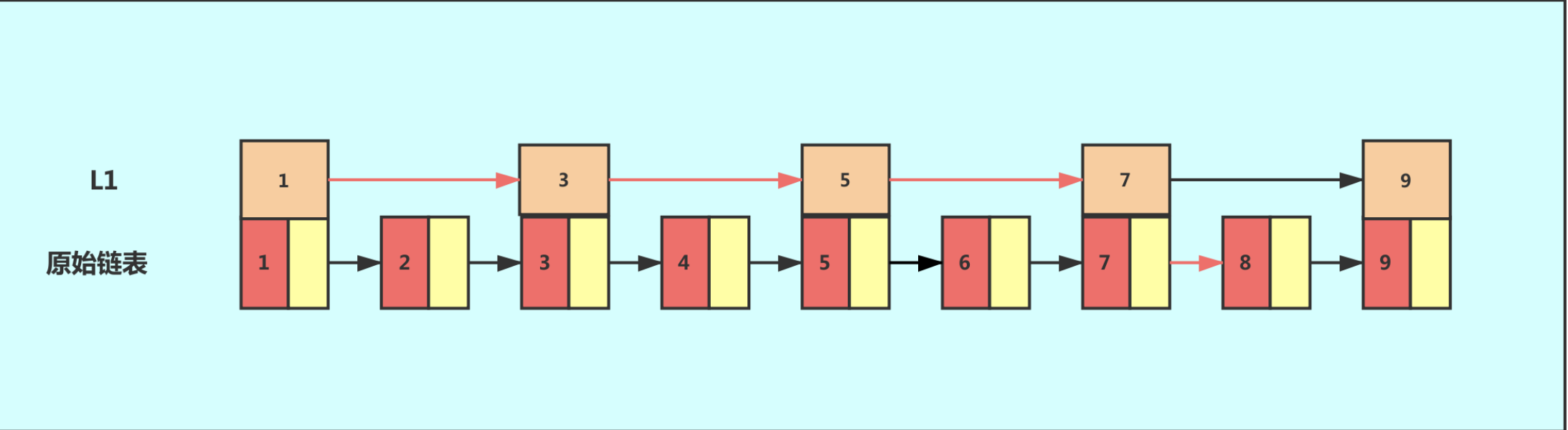
如果我们想要提高其查找效率,可以考虑在链表上建索引的方式。每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引。
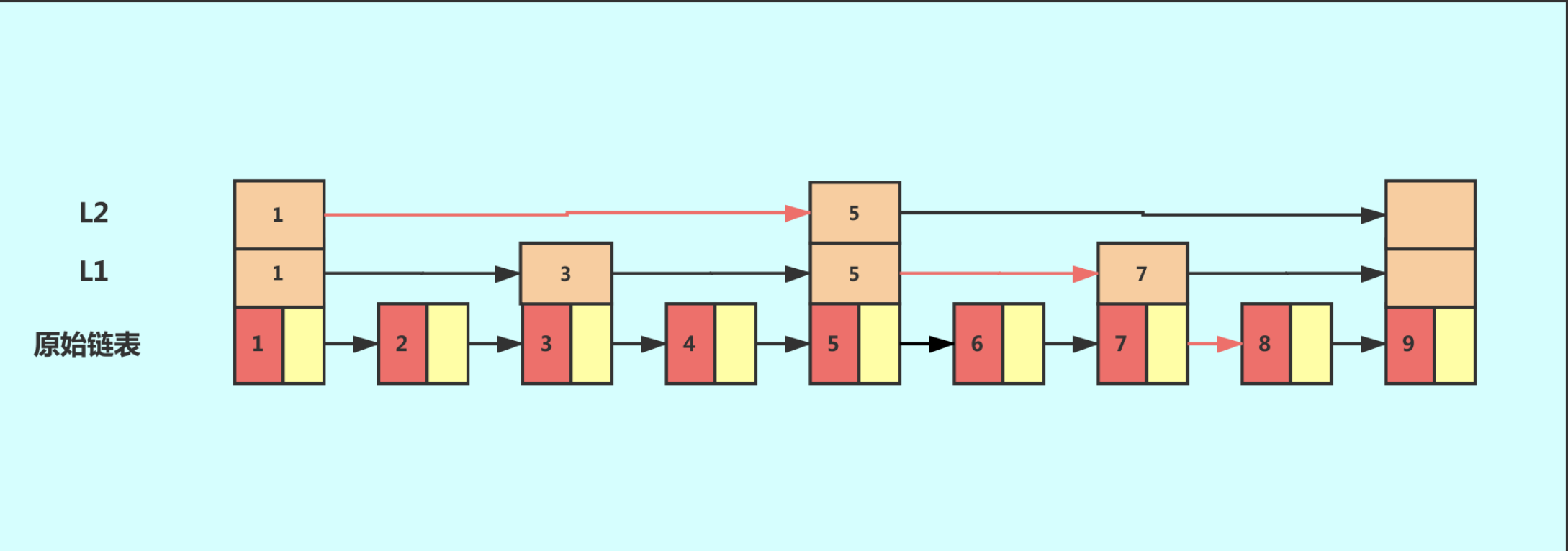
这个时候,我们假设要查找节点8,我们可以先在索引层遍历,当遍历到索引层中值为 7 的结点时,发现下一个节点是9,那么要查找的节点8肯定就在这两个节点之间。我们下降到链表层继续遍历就找到了8这个节点。原先我们在单链表中找到8这个节点要遍历8个节点,而现在有了一级索引后只需要遍历五个节点。
从这个例子里,我们看出,加来一层索引之后,查找一个结点需要遍的结点个数减少了,也就是说查找效率提高了,同理再加一级索引。
从图中可以看出,查找效率又有提升。在例子中我们的数据很少,当有大量的数据时,我们可以增加多级索引,其查找效率可以得到明显提升,时间复杂度趋近于平衡树O(logn)。
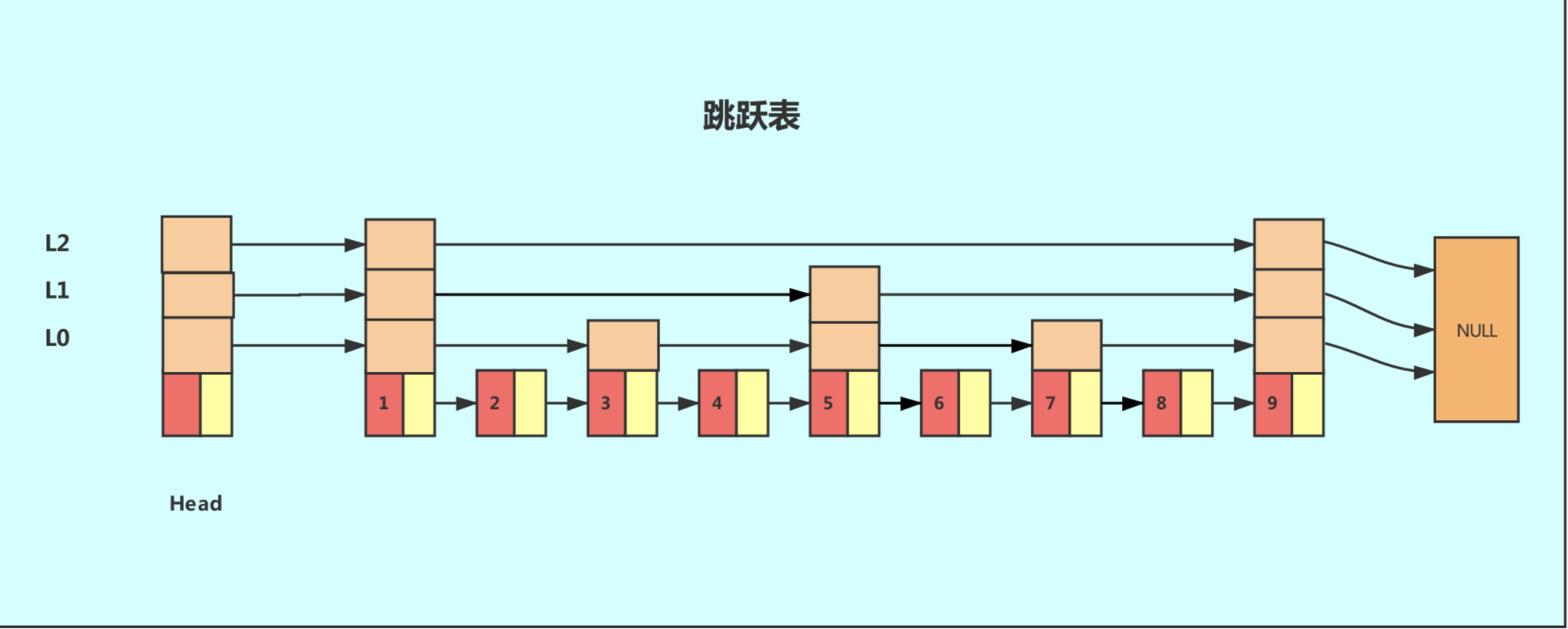
像这种链表加索引的数据结构,就是跳跃表。
Redis 跳跃表
Redis 使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时, Redis 就会使用跳跃表来作为有序集合健的底层实现。
这里我们需要思考一个问题——为什么元素数量比较多或者成员是比较长的字符串的时候 Redis 要使用跳跃表来实现?
从上面我们可以知道,跳跃表在链表的基础上增加了多级索引以提升查找的效率,但其是一个空间换时间的方案,必然会带来一个问题——索引是占内存的。原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值值和几个指针,并不需要存储对象,因此当节点本身比较大或者元素数量比较多的时候,其优势必然会被放大,而缺点则可以忽略。
Redis 跳跃表的实现
Redis 的跳跃表由 zskiplistNode 和 skiplist 两个结构定义,其中 zskiplistNode 结构用于表示跳跃表节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。
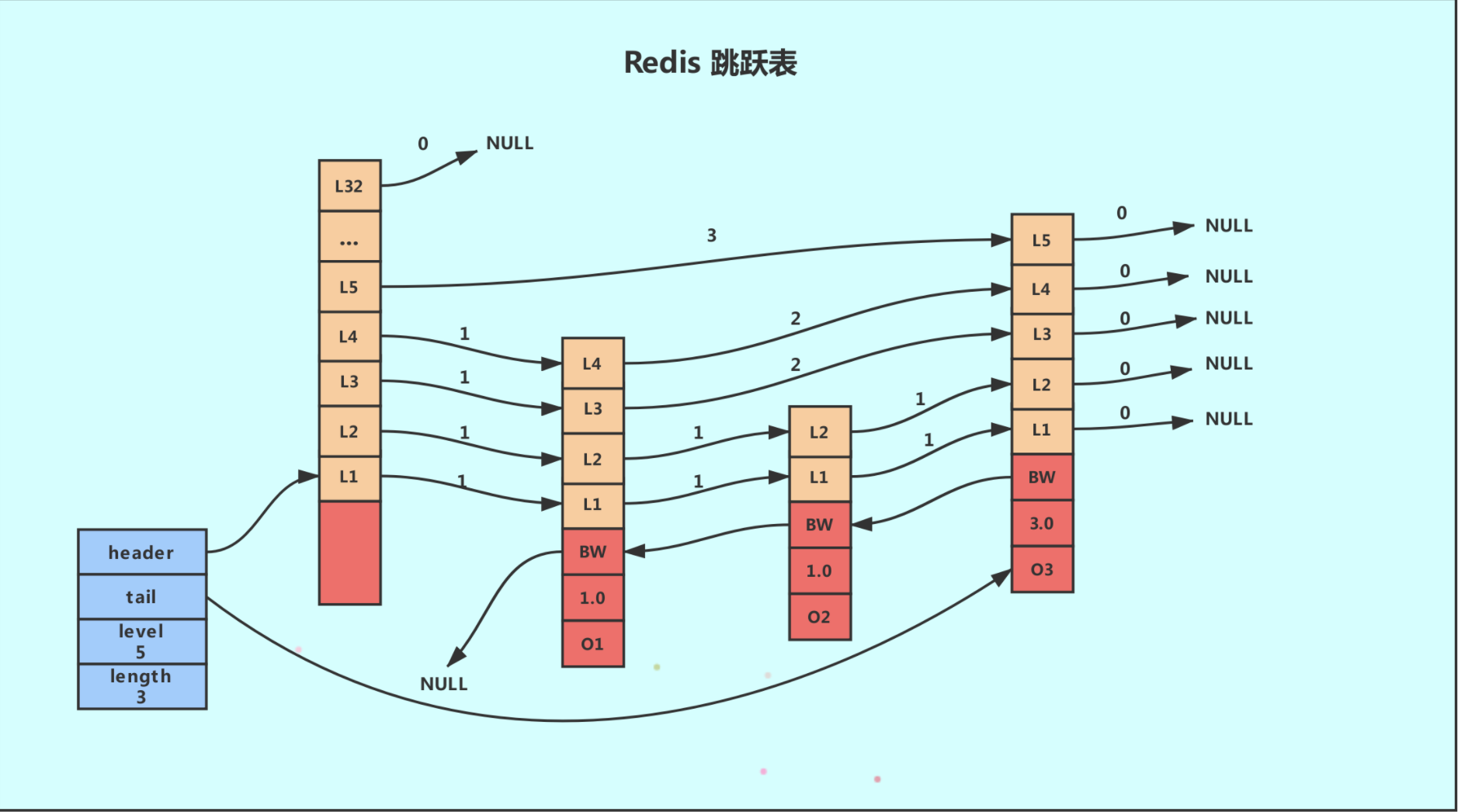
上图展示了一个跳跃表示例,其中最左边的是 skiplist 结构,该结构包含以下属性。
- header:指向跳跃表的表头节点,通过这个指针程序定位表头节点的时间复杂度就为 O(1)
- tail:指向跳跃表的表尾节点,通过这个指针程序定位表尾节点的时间复杂度就为 O(1)
- level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内),通过这个属性可以在 O(1) 的时间复杂度内获取层高最高的节点的层数。
- length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内),通过这个属性,程序可以在 O(1) 的时间复杂度内返回跳跃表的长度。
结构右方的是四个 zskiplistNode 结构,该结构包含以下属性
层(level):
节点中用 1、2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表第二层,以此类推。
每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离(跨度越大、距离越远)。在上图中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
每次创建一个新跳跃表节点的时候,程序都根据幂次定律(powerlaw,越大的数出现的概率越小)随机生成一个介于 1 和 32 之间的值作为 level 数组的大小,这个大小就是层的“高度”。
后退(backward)指针:
节点中用BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。与前进指针所不同的是每个节点只有一个后退指针,因此每次只能后退一个节点。
分值(score):
各个节点中的1.0、2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
成员对象(oj):
各个节点中的 o1、o2 和 o3 是节点所保存的成员对象。在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值却可以是相同的:分值相同的节点将按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
Redis 跳跃表常用操作的时间复杂度
| 操作 | 时间复杂度 |
|---|---|
| 创建一个跳跃表 | O(1) |
| 释放给定跳跃表以及其中包含的节点 | O(N) |
| 添加给定成员和分值的新节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 删除除跳跃表中包含给定成员和分值的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 返回给定成员和分值的节点再表中的排位 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 返回在给定排位上的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 给定一个分值范围,返回跳跃表中第一个符合这个范围的节点 | O(1) |
| 给定一个分值范围,返回跳跃表中最后一个符合这个范围的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 给定一个分值范围,除跳跃表中所有在这个范围之内的节点 | 平均O(logN),最坏O(logN)(N为跳跃表的长度) |
| 给定一个排位范围,鼎除跳跃表中所有在这个范围之内的节点 | O(N),N为被除节点数量 |
| 给定一个分值范固(range),比如0到15,20到28,诸如此类,如果跳氏表中有至少一个节点的分值在这个范間之内,那么返回1,否则返回0 | O(N),N为被除节点数量 |
有序列表 zset 基础操作
1 | ZADD books 9.0 "think in java" |
四、持久化
Redis 是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好 Redis 还为我们提供了持久化的机制,分别是 RDB(Redis DataBase) 和 AOF(Append Only File)。
持久化流程
持久化流程主要包含下面五个过程:
客户端向服务端发送写操作(数据在客户端的内存中)。
数据库服务端接收到写请求的数据(数据在服务端的内存中)。
服务端调用 write 这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这五个过程是在理想条件下的一次正常保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
(1)Redis 数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
(2)操作系统发生故障,必须上面五步都完成才可以。
在这里只考虑了保存的过程可能发生的故障,其实保存的数据也有可能发生损坏,需要一定的恢复机制,不过在这里就不再延伸了。现在主要考虑的是 Redis 如何来实现上面五个保存磁盘的步骤。它提供了两种策略机制,也就是 RDB 和 AOF。
RDB 机制
RDB 其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB 持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为 dump.rdb。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,是实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化。
save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
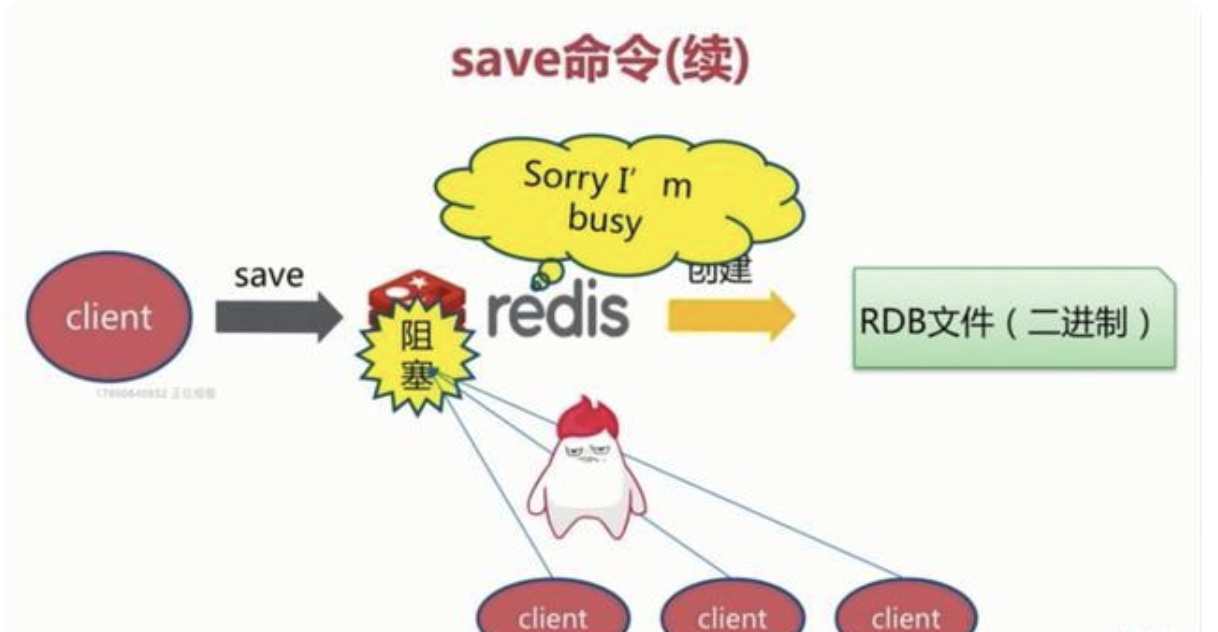
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取.
bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
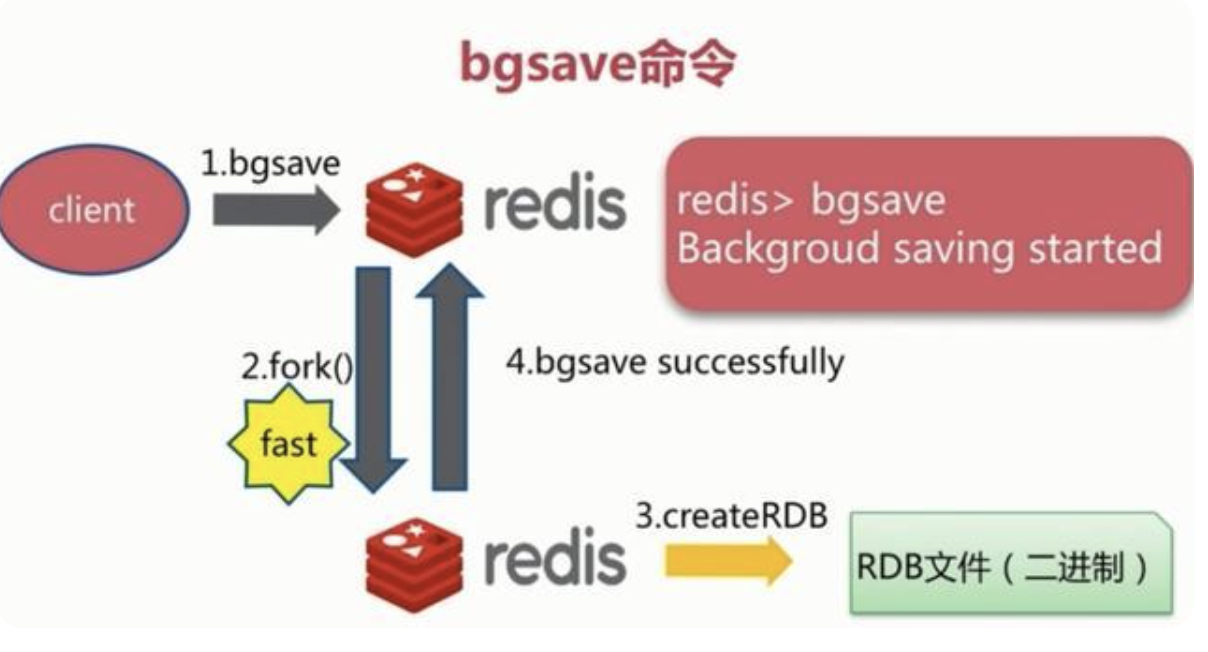
Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork 阶段,一般时间很短。基本上 Redis 内部所有的 RDB 操作都是采用 bgsave 命令。
自动触发
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置
save:这里是用来配置触发 Redis 的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示 m 秒内数据集存在 n 次修改时,自动触发 bgsave。
默认如下配置:
#表示900 秒内如果至少有 1 个 key 的值变化,则保存save 900 1#表示300 秒内如果至少有 10 个 key 的值变化,则保存save 300 10#表示60 秒内如果至少有 10000 个 key 的值变化,则保存save 60 10000
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
stop-writes-on-bgsave-error:默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
rdbcompression :默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename :设置快照的文件名,默认是 dump.rdb
dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
除了按照自动触发配置的规则执行 RDB 外,还有其他情况也会自动执行 RDB,如:
1)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
2)执行debug reload命令重新加载Redis时,也会自动触发save操作。
3)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave。
RDB 的优劣
优势:
- RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势:
- 在快照持久化期间修改的数据不会被保存,可能丢失数据。
AOF 机制
AOF(append only file)持久化:以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用 是解决了数据持久化的实时性。
每当有一个写命令过来时,就直接保存在我们的 AOF 文件中。同时带来了另一个问题:持久化文件会变的越来越大。为了压缩 AOF 的持久化文件。Redis 提供了 bgrewriteaof 命令。将内存中的数据以命令的方式保存到临时文件中,同时会 fork 出一条新进程来将文件重写。
为了防止文件无限变大,4.0 以前会重写日志,删除抵消命令,合并重复命令。4.0 以后重写是将老的数据 rdb 方式保存,在后面追加新的数据 aof
触发机制
- always: 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
- everysec: 异步操作,每秒记录 如果一秒内宕机,有数据丢失
- no: 从不同步
AOF 的优劣
优势:
- 数据可读
- 完整性更高
劣势:
- 相较于 RDB ,AOF 文件较大
- AOF 支持的读并发较低。
重启时的数据恢复
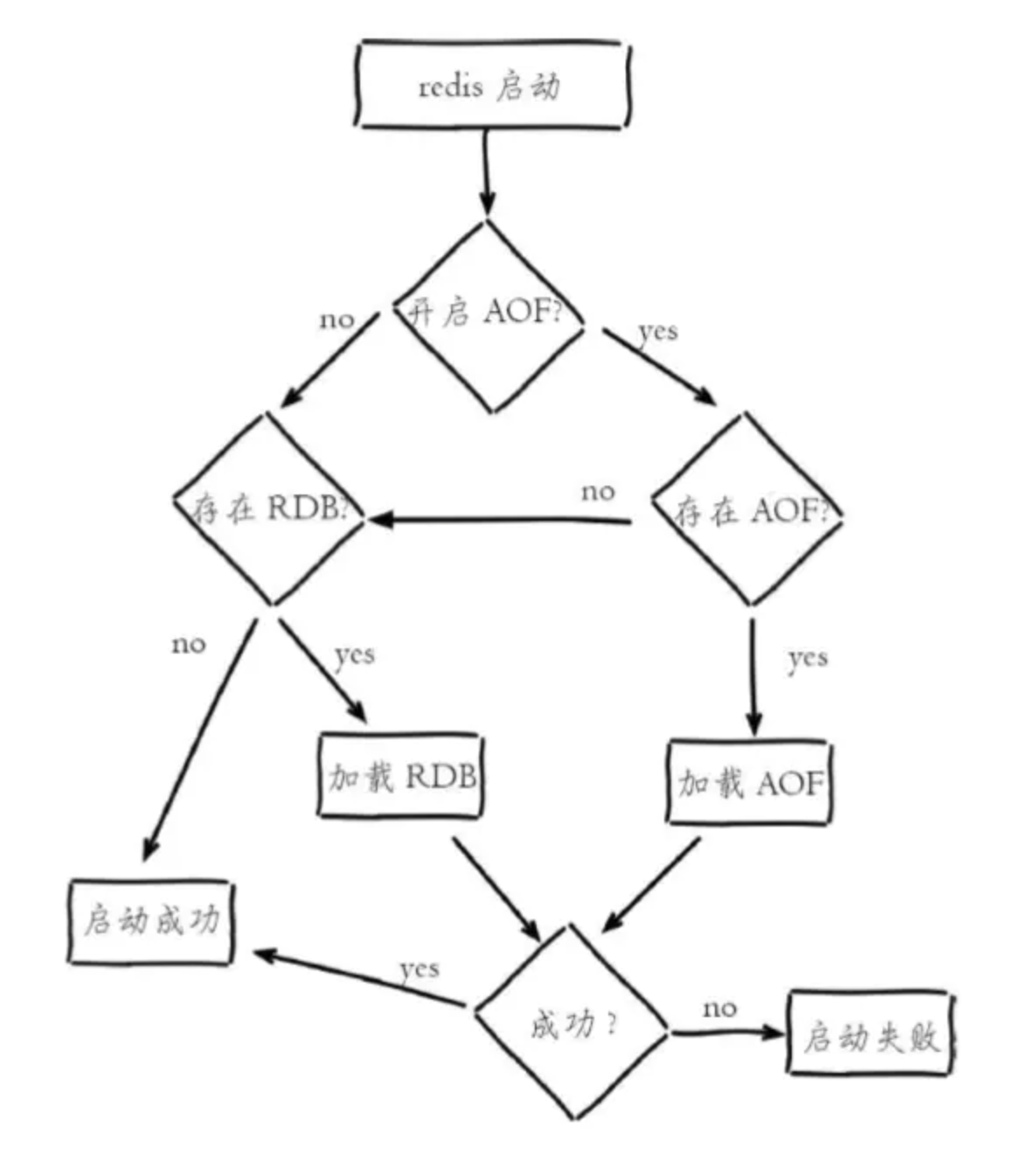
流程说明:
1)AOF持久化开启且存在AOF文件时,优先加载AOF文件,打印如下日志:
DB loaded from append only file: 5.841 seconds
2)AOF关闭或者AOF文件不存在时,加载RDB文件,打印如下日志:
DB loaded from disk: 5.586 seconds
3)加载AOF/RDB文件成功后,Redis启动成功。
4)AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
五、事务和 Watch
严格意义来讲,Redis 的事务和我们理解的传统数据库 (如 mysql) 的事务是不一样的。
redis中的事务定义
Redis 中的事务(transaction)是一组命令的集合。
- 事务同命令一样都是 Redis 的最小执行单位,一个事务中的命令要么都执行,要么都不执行。
- 事务的原理是先将属于一个事务的命令发送给 Redis ,然后再让 Redis 依次执行这些命令。
Redis 保证一个事务中的所有命令要么都执行,要么都不执行。如果在发送 EXEC 命令前客户端断线了,则 Redis 会清空事务队列,事务中的所有命令都不会执行。而一旦客户端发送了 EXEC 命令,所有的命令就都会被执行,即使此后客户端断线也没关系,因为 Redis 中已经记录了所有要执行的命令。
除此之外,Redis 的事务还能保证一个事务内的命令依次执行而不被其他命令插入。试想客户端 A 需要执行几条命令,同时客户端 B 发送了一条命令,如果不使用事务,则客户端 B 的命令可能会插入到客户端 A 的几条命令中执行。如果不希望发生这种情况,也可以使用事务。
事务的应用
事务的应用非常普遍,如银行转账过程中 A 给 B 汇款,首先系统从 A 的账户中将钱划走,然后向 B 的账户增加相应的金额。这两个步骤必须属于同一个事务,要么全执行,要么全不执行。否则只执行第一步,钱就凭空消失了,这显然让人无法接受。
和传统的mysql事务不同的事,即使我们的加钱操作失败,我们也无法在这一组命令中让整个状态回滚到操作之前
事务的错误处理
如果一个事务中的某个命令执行出错,Redis 会怎样处理呢?要回答这个问题,首先需要知道什么原因会导致命令执行出错。
语法错误
语法错误指命令不存在或者命令参数的个数不对。比如:
1 | redis>MULTI |
跟在 MULTI 命令后执行了 3 个命令:一个是正确的命令,成功地加入事务队列;其余两个命令都有语法错误。而只要有一个命令有语法错误,执行 EXEC 命令后 Redis 就会直接返回错误,连语法正确的命令也不会执行。
这里需要注意一点:
Redis 2.6.5 之前的版本会忽略有语法错误的命令,然后执行事务中其他语法正确的命令。就此例而言,SET key value 会被执行,EXEC 命令会返回一个结果:1) OK。
运行错误
运行错误指在命令执行时出现的错误,比如使用散列类型的命令操作集合类型的键,这种错误在实际执行之前 Redis 是无法发现的,所以在事务里这样的命令是会被 Redis 接受并执行的。如果事务里的一条命令出现了运行错误,事务里其他的命令依然会继续执行(包括出错命令之后的命令),示例如下:
1 | redis>MULTI |
可见虽然SADD key 2出现了错误,但是SET key 3依然执行了。
Redis 的事务没有关系数据库事务提供的回滚(rollback)功能。为此开发者必须在事务执行出错后自己收拾剩下的摊子(将数据库复原回事务执行前的状态等,这里我们一般采取日志记录然后业务补偿的方式来处理,但是一般情况下,在 Redis 做的操作不应该有这种强一致性要求的需求,我们认为这种需求为不合理的设计)。
Redis 事务对 ACID 的支持
Redis 确实是有事务,不过按照传统的事务定义 ACID 来看,Redis 是不是都具备了 ACID 的特性。
1、原子性
事务具备原子性指的是,数据库将事务中多个操作当作一个整体来执行,服务要么执行事务中所有的操作,要么一个操作也不会执行。
①事务队列
首先弄清楚 Redis 开始事务 multi 命令后,Redis 会为这个事务生成一个队列,每次操作的命令都会按照顺序插入到这个队列中。
这个队列里面的命令不会被马上执行,直到 exec 命令提交事务,所有队列里面的命令会被一次性,并且排他的进行执行。对应如下图:
从上面的例子可以看出,当执行一个成功的事务,事务里面的命令都是按照队列里面顺序的并且排他的执行。
但原子性又一个特点就是要么全部成功,要么全部失败,也就是我们传统 DB 里面说的回滚。
当我们执行一个失败的事务
可以发现,就算中间出现了失败,set abc x 这个操作也已经被执行了,并没有进行回滚,从严格的意义上来说 Redis 并不具备原子性。
②为何 Redis 不支持回滚
这个其实跟 Redis 的定位和设计有关系,先看看为何我们的 MySQL 可以支持回滚,这个还是跟写 Log 有关系,Redis 是完成操作之后才会进行 AOF 日志记录,AOF 日志的定位只是记录操作的指令记录。
而 MySQL 有完善的 Redolog,并且是在事务进行 Commit 之前就会写完成 Redolog,Binlog:要知道 MySQL 为了能进行回滚是花了不少的代价,Redis 应用的场景更多是对抗高并发具备高性能,所以 Redis 选择更简单,更快速无回滚的方式处理事务也是符合场景。
2、一致性
事务具备一致性指的是,如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否成功,数据库也应该是一致的。
从 Redis 来说可以从 2 个层面看,一个是执行错误是否有确保一致性,另一个是宕机时,Redis 是否有确保一致性的机制。
①执行错误是否有确保一致性
依然去执行一个错误的事务,在事务执行的过程中会识别出来并进行错误处理,这些错误并不会对数据库作出修改,也不会对事务的一致性产生影响。
②宕机对一致性的影响
暂不考虑分布式高可用的 Redis 解决方案,先从单机看宕机恢复是否能满意数据完整性约束。
无论是 RDB 还是 AOF 持久化方案,可以使用 RDB 文件或 AOF 文件进行恢复数据,从而将数据库还原到一个一致的状态。
③再议一致性
上面执行错误和宕机对一致性的影响的观点摘自黄健宏 《Redis 设计与实现》。
当在读这章的时候还是有一些存疑的点,归根到底 Redis 并非关系型数据库。
如果仅仅就 ACID 的表述上来说,一致性就是从 A 状态经过事务到达 B 状态没有破坏各种约束性,仅就 Redis 而言不谈实现的业务,那显然就是满足一致性。
但如果加上业务去谈一致性,例如,A 转账给 B,A 减少 10 块钱,B 增加 10 块钱,因为 Redis 并不具备回滚,也就不具备传统意义上的原子性,所以 Redis 也应该不具备传统的一致性。
其实,这里只是简单讨论下 Redis 在传统 ACID 上的概念怎么进行对接,或许,有可能是我想多了,用传统关系型数据库的 ACID 去审核 Redis 是没有意义的,Redis 本来就没有意愿去实现 ACID 的事务。
3、隔离性
隔离性指的是,数据库中有多个事务并发的执行,各个事务之间不会相互影响,并且在并发状态下执行的事务和串行执行的事务产生的结果是完全相同的。
Redis 因为是单线程操作,所以在隔离性上有天生的隔离机制,当 Redis 执行事务时,Redis 的服务端保证在执行事务期间不会对事务进行中断,所以,Redis 事务总是以串行的方式运行,事务也具备隔离性。
4、持久性
事务的持久性指的是,当一个事务执行完毕,执行这个事务所得到的结果被保存在持久化的存储中,即使服务器在事务执行完成后停机了,执行的事务的结果也不会被丢失。
Redis 是否具备持久化,这个取决于 Redis 的持久化模式:
- 纯内存运行,不具备持久化,服务一旦停机,所有数据将丢失。
- RDB 模式,取决于 RDB 策略,只有在满足策略才会执行 Bgsave,异步执行并不能保证 Redis 具备持久化。
- AOF 模式,只有将 appendfsync 设置为 always,程序才会在执行命令同步保存到磁盘,而且在这个模式下,这种保存是由后台线程进行的,主线程不会阻塞直到保存成功,所以从命令执行成功到数据保存到硬盘之间,还是有一段非常小的间隔,所以这种模式下的事务也是不持久的。
简单总结:
- Redis 事务不具备原子性,不支持回滚。
- Redis 不具备一致性的概念。(或者说 Redis 在设计时就无视这点)
- Redis 天生具备隔离性。
- Redis 不具备严格的持久性。
Redis 和 ACID 纯属站在使用者的角度去思想,Redis 设计更多的是追求简单与高性能,不会受制于传统 ACID 的束缚。
Watch 命令
大家可能知道 Redis 提供了基于 incr 命令来操作一个整数型数值的原子递增,那么我们假设如果 Redis 没有这个 incr 命令,我们该怎么实现这个 incr 的操作呢?
那么我们下面的正主***watch***就要上场了。
如何使用 watch 命令
正常情况下我们想要对一个整形数值做修改是这么做的(伪代码实现):
1 | val = GET mykey |
但是上述的代码会出现一个问题,因为上面把正常的一个 incr(原子递增操作) 分为了两部分,那么在*多线程(分布式)*环境中,这个操作就有可能不再具有原子性了。
研究过 Java 的 JUC 包的人应该都知道 CAS,那么 Redis 也提供了这样的一个机制,就是利用watch命令来实现的。
watch 命令描述
WATCH 命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。监控一直持续到 EXEC 命令(事务中的命令是在 EXEC 之后才执行的,所以在 MULTI 命令后可以修改 WATCH 监控的键值)
利用 watch 实现 incr
具体做法如下:
1 | WATCH mykey |
和此前代码不同的是,新代码在获取 mykey 的值之前先通过 WATCH 命令监控了该键,此后又将 set 命令包围在事务中,这样就可以有效的保证每个连接在执行 EXEC 之前,如果当前连接获取的 mykey 的值被其它连接的客户端修改,那么当前连接的 EXEC 命令将执行失败。这样调用者在判断返回值后就可以获悉 val 是否被重新设置成功。
注意点
由于 WATCH 命令的作用只是当被监控的键值被修改后阻止之后一个事务的执行,而不能保证其他客户端不修改这一键值,所以在一般的情况下我们需要在 EXEC 执行失败后重新执行整个函数。
执行 EXEC 命令后会取消对所有键的监控,如果不想执行事务中的命令也可以使用 UNWATCH 命令来取消监控。
实现一个 hsetNX 函数
我们实现的 hsetNX 这个功能是:仅当字段存在时才赋值。
为了避免竞态条件我们使用watch和事务来完成这一功能(伪代码):
1 | WATCH key |
在代码中会判断要赋值的字段是否存在,如果字段不存在的话就不执行事务中的命令,但需要使用 UNWATCH 命令来保证下一个事务的执行不会受到影响。
六、数据过期时间及内存淘汰机制
Redis 的过期策略
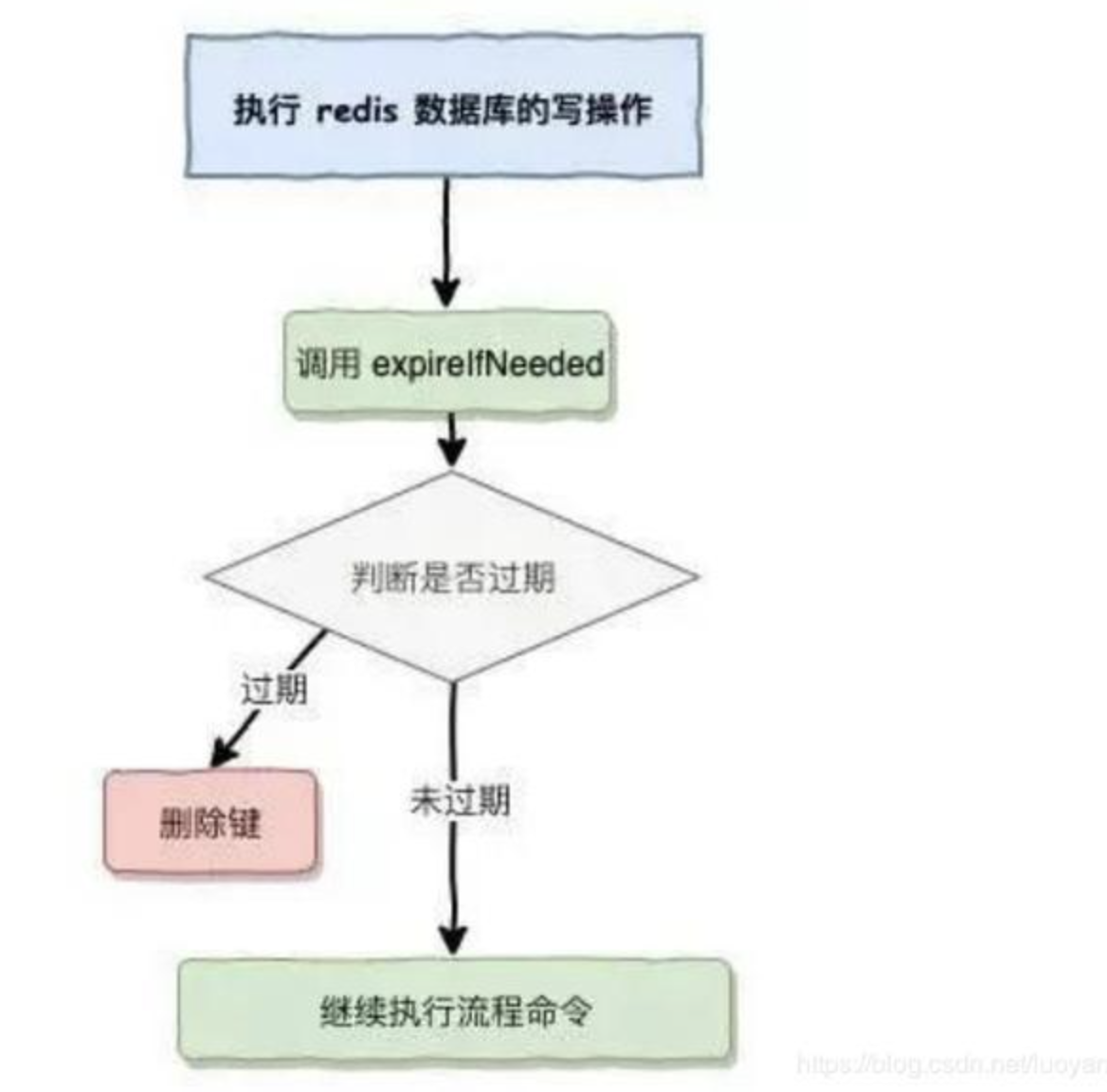
Redis 在设置缓存数据时指定了过期时间,到了过期时间数据就失效了,那 Redis 是怎么处理这些失效的数据的呢?这就用到了Redis的过期策略——“==定期删除+惰性删除==” 。
定期删除
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
- 从过期字典中随机 20 个 key;
- 删除这 20 个 key 中已经过期的 key;
- 如果过期的 key 比率超过 1/4,那就重复步骤 1;
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
如果某一时刻,有大量key同时过期,Redis 会持续扫描过期字典,造成客户端响应卡顿,因此设置过期时间时,就尽量避免这个问题,在设置过期时间时,可以给过期时间设置一个随机范围,避免同一时刻过期。
如何配置定期删除执行时间间隔
redis的定时任务默认是10s执行一次,如果要修改这个值,可以在redis.conf中修改hz的值。
redis.conf中,hz默认设为10,提高它的值将会占用更多的cpu,当然相应的redis将会更快的处理同时到期的许多key,以及更精确的去处理超时。 hz的取值范围是1~500,通常不建议超过100,只有在请求延时非常低的情况下可以将值提升到100。
单线程的redis,如何知道要运行定时任务?
redis是单线程的,线程不但要处理定时任务,还要处理客户端请求,线程不能阻塞在定时任务或处理客户端请求上,那么,redis是如何知道何时该运行定时任务的呢?
Redis 的定时任务会记录在一个称为最小堆的数据结构中。这个堆中,最快要执行的任务排在堆的最上方。在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是接下来处理客户端请求的最大时长,若达到了该时长,则暂时不处理客户端请求而去运行定时任务。
惰性删除
定时删除策略中,从删除方法来看,必然会导致有key过期了但未从redis中删除的情况。
面对这种情况,redis在操作一个key时,会先判断这个值是否过期,若已过期,则删除该key;若未过期,则进行后续操作。
AOF/RDB 和复制功能对过期键的处理
RDB
- 生成 RDB 文件:生成时,程序会对键进行检查,过期键不放入 RDB 文件。
- 载入 RDB 文件:载入时,如果以主服务器模式运行,程序会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期键则会忽略;如果以从服务器模式运行,无论键过期与否,均会载入数据库中,过期键会通过与主服务器同步而删除。
AOF
- 当服务器以 AOF 持久化模式运行时,如果数据库中的某个键已经过期,但它还没有被删除,那么aof文件不会因为这个过期键而产生任何影响;当过期键被删除后,程序会向 AOF 文件追加一条 del 命令来显式记录该键已被删除。
- AOF 重写过程中,程序会对数据库中的键进行检查,已过期的键不会被保存到重写后的 AOF 文件中。
复制
当服务器运行在复制模式下时,从服务器的过期删除动作由主服务器控制:
- 主服务器在删除一个过期键后,会显式地向所有从服务器发送一个 del 命令,告知从服务器删除这个过期键;
- 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键;
- 从服务器只有在接到主服务器发来的 del 命令后,才会删除过期键。
不管是定期采样删除还是惰性删除都不是一种完全精准的删除,就还是会存在key没有被删除掉的场景,所以就需要内存淘汰策略进行补充。
内存淘汰策略
内存淘汰策略可选项
- noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
- allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
- volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
- allkeys-random:加入键的时候如果过限,从所有key随机删除
- volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
- volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
- volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu:从所有键中驱逐使用频率最少的键
LRU
标准 LRU 实现方式
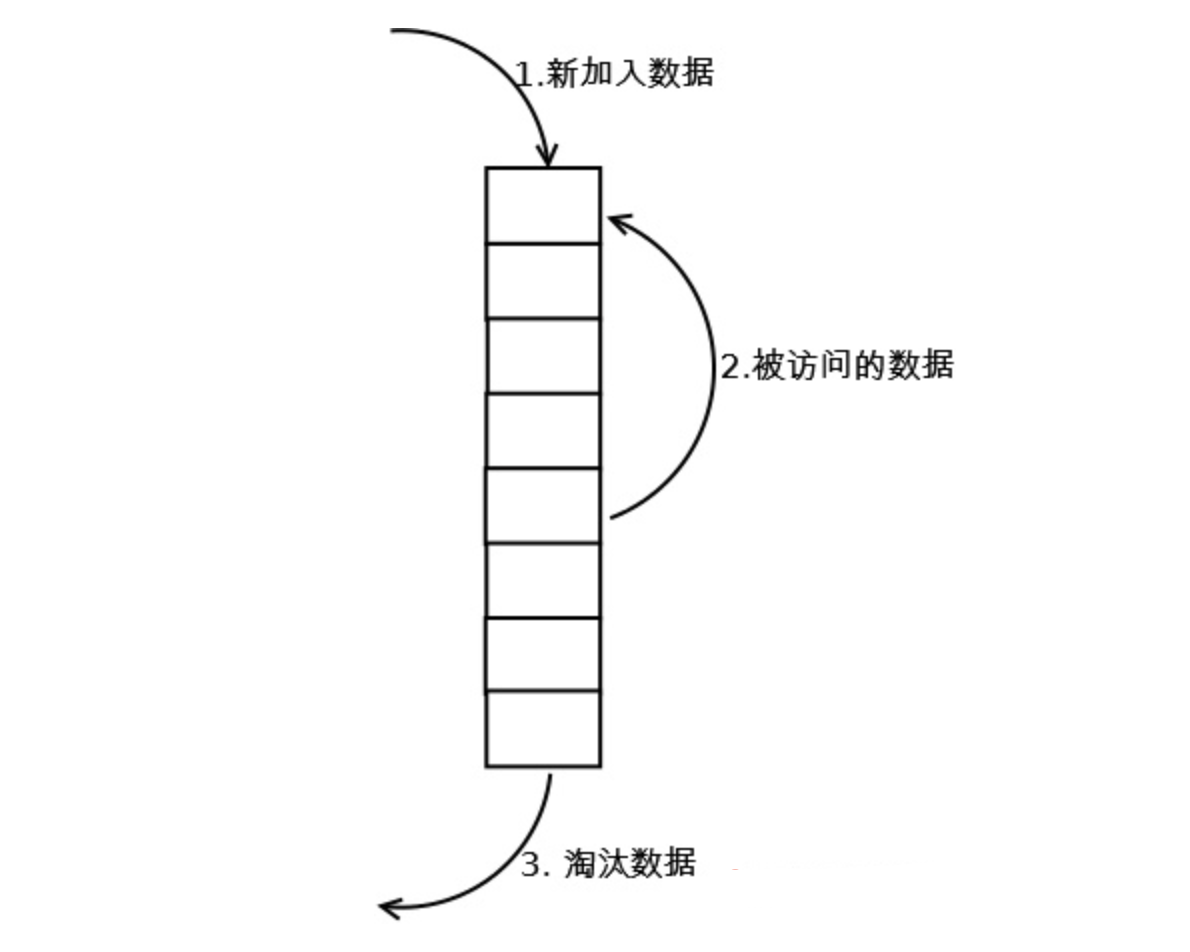
- 新增key value的时候首先在链表结尾添加Node节点,如果超过LRU设置的阈值就淘汰队头的节点并删除掉HashMap中对应的节点。
- 修改key对应的值的时候先修改对应的Node中的值,然后把Node节点移动队尾。
- 访问key对应的值的时候把访问的Node节点移动到队尾即可。
Java LinkedHashMap 实现 LRU
1 | public class LRUCache extends LinkedHashMap { |
Redis 的 LRU 实现
Redis维护了一个24位时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟。每个key对象内部同样维护了一个24位的时钟,当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有24位,按秒为单位来表示才能存储194天,所以可能会出现key的时钟大于全局时钟的情况,如果这种情况出现那么就两个相加而不是相减来求最久的key。
1 | struct redisServer { |
Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。
LFU
LFU 是在 Redis4.0 后出现的,LRU 的最近最少使用实际上并不精确,考虑下面的情况,如果在|处删除,那么 A 距离的时间最久,但实际上 A 的使用频率要比 B 频繁,所以合理的淘汰策略应该是淘汰 B。LFU 就是为应对这种情况而生的。LFU 把原来的 key 对象的内部时钟的 24 位分成两部分,其中高16 bits用来记录计数器的上次缩减时间,时间戳,单位精确到分钟。低8 bits用来记录计数器的当前数值,8 位只能代表 255,但是 Redis 并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置如下两个参数来调整数据的递增速度。
AAAAAAAAA~~A~~~|
B~~~~~B~~~~~B~~~~~B~~~~~~~~~~~~B|
存在问题:
因为访问频率是动态变化的,前段时间频繁访问的key,之后也可能很少再访问(如微博热搜)。为了解决这个问题,Redis记录了每个key最后一次被访问的时间,随着时间的推移,如果某个key再没有被访问过,计数器的值也会逐渐降低。
新生key问题,对于新加入缓存的key,因为还没有被访问过,计数器的值如果为0,就算这个key是热点key,因为计数器值太小,也会被淘汰机制淘汰掉。为了解决这个问题,Redis会为新生key的计数器设置一个初始值。
LFU 把原来的 key 对象的内部时钟的 24 位分成两部分,前 16 位还代表时钟,后 8 位代表一个计数器。16 位的情况下如果还按照秒为单位就会导致不够用,所以一般这里以时钟为单位。而后 8 位表示当前 key 对象的访问频率,8 位只能代表 255,但是 Redis 并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置如下两个参数来调整数据的递增速度。
lfu-log-factor 可以调整计数器 counter 的增长速度,lfu-log-factor 越大,counter 增长的越慢。
lfu-decay-time 是一个以分钟为单位的数值,可以调整 counter 的减少速度。
七、主从复制(读写分离)
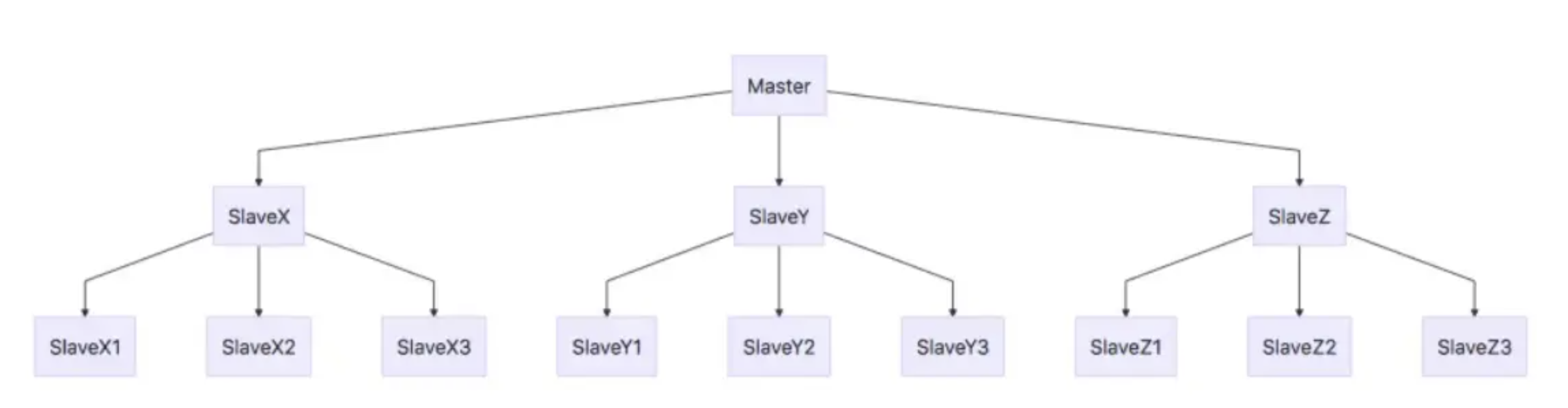
主从复制的作用
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。
为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
总结:引入主从复制机制的目的有两个
- 一个是读写分离,分担 “master” 的读写压力
- 一个是方便做容灾恢复
主从复制的原理
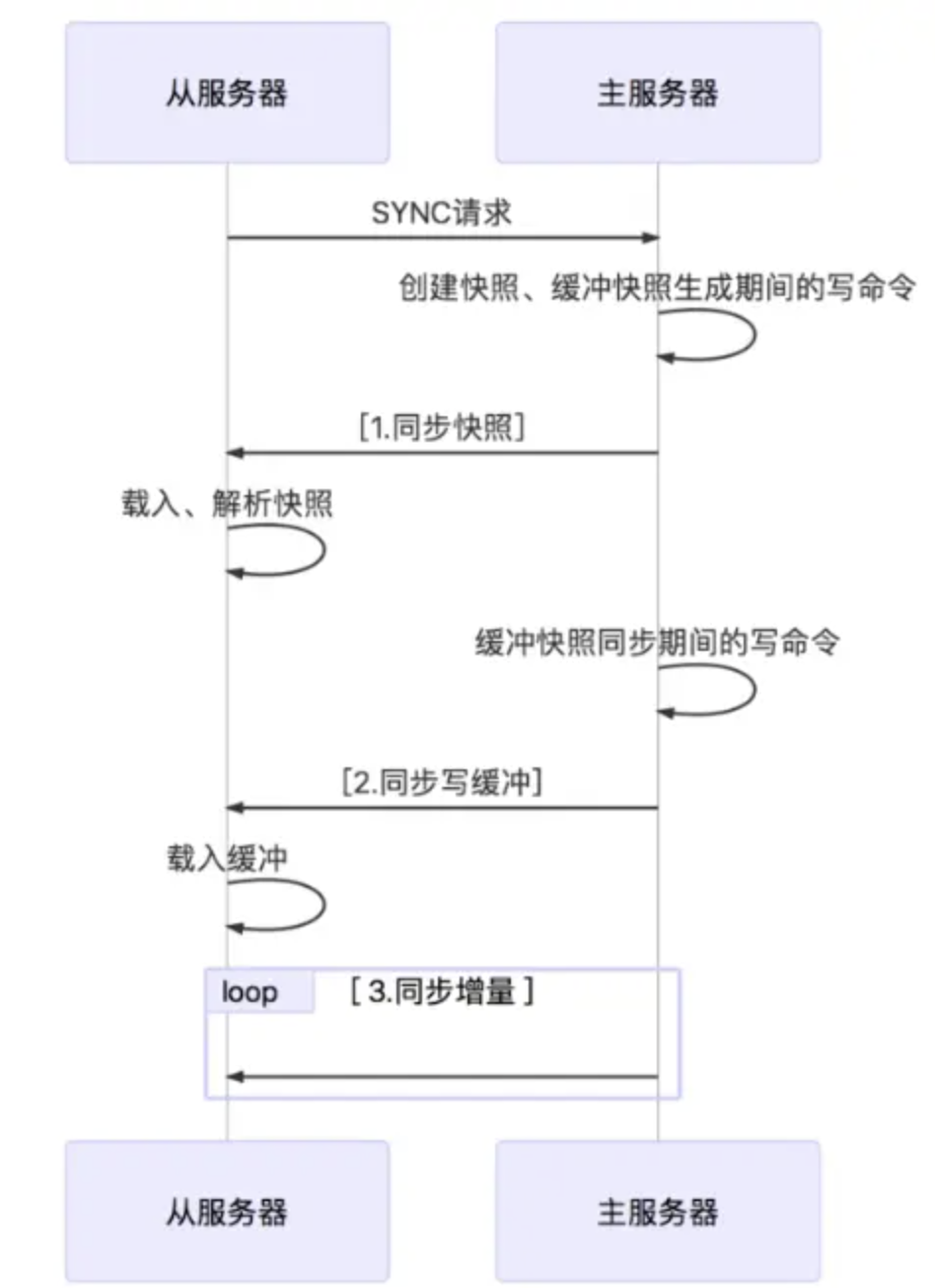
- 从数据库启动成功后,连接主数据库,发送 SYNC 命令;
- 主数据库接收到 SYNC 命令后,开始执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令;
- 主数据库 BGSAVE 执行完后,向所有从数据库发送快照文件,并在发送期间继续记录被执行的写命令;
- 从数据库收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主数据库快照发送完毕后开始向从数据库发送缓冲区中的写命令;
- 从数据库完成对快照的载入,开始接收命令请求,并执行来自主数据库缓冲区的写命令;(从数据库初始化完成)
- 主数据库每执行一个写命令就会向从数据库发送相同的写命令,从数据库接收并执行收到的写命令(从数据库初始化完成后的操作)
- 出现断开重连后,2.8之后的版本会将断线期间的命令传给重数据库,增量复制。
- 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。Redis 的策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
主从复制优缺点
主从复制优点
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离;
- 为了分载 Master 的读操作压力,Slave 服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成;
- Slave 同样可以接受其它 Slaves 的连接和同步请求,这样可以有效的分载 Master 的同步压力;
- Master Server 是以非阻塞的方式为 Slaves 提供服务。所以在 Master-Slave 同步期间,客户端仍然可以提交查询或修改请求;
- Slave Server 同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据;
主从复制缺点
- Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复(也就是要人工介入);
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性;
- 如果多个 Slave 断线了,需要重启的时候,尽量不要在同一时间段进行重启。因为只要 Slave 启动,就会发送sync 请求和主机全量同步,当多个 Slave 重启的时候,可能会导致 Master IO 剧增从而宕机。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
部署示例
主要有两步
- 准备 master/slave 配置文件
- 先启动 master 再启动 slave,进行验证
节点规划
| 节点 | 配置文件 | 端口 |
|---|---|---|
| master | redis6379.conf | 6379 |
| slave1 | redis6380.conf | 6380 |
| slave1 | redis6381.conf | 6380 |
配置文件
1 | # redis6379.conf master |
启动节点
启动节点,然后查看节点信息
1 | 顺序启动节点 |
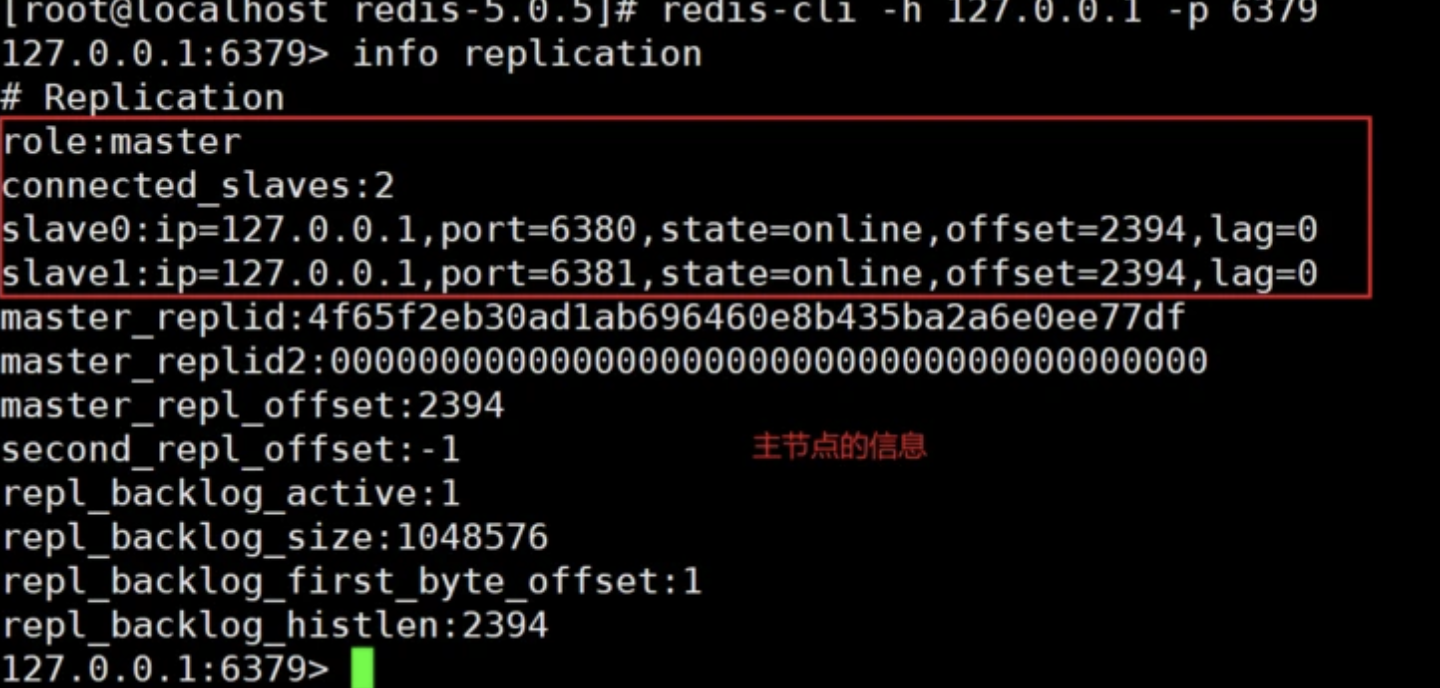
info replication 命令可以查看连接该数据库的其它库的信息,可看到有两个 slave 连接到 master
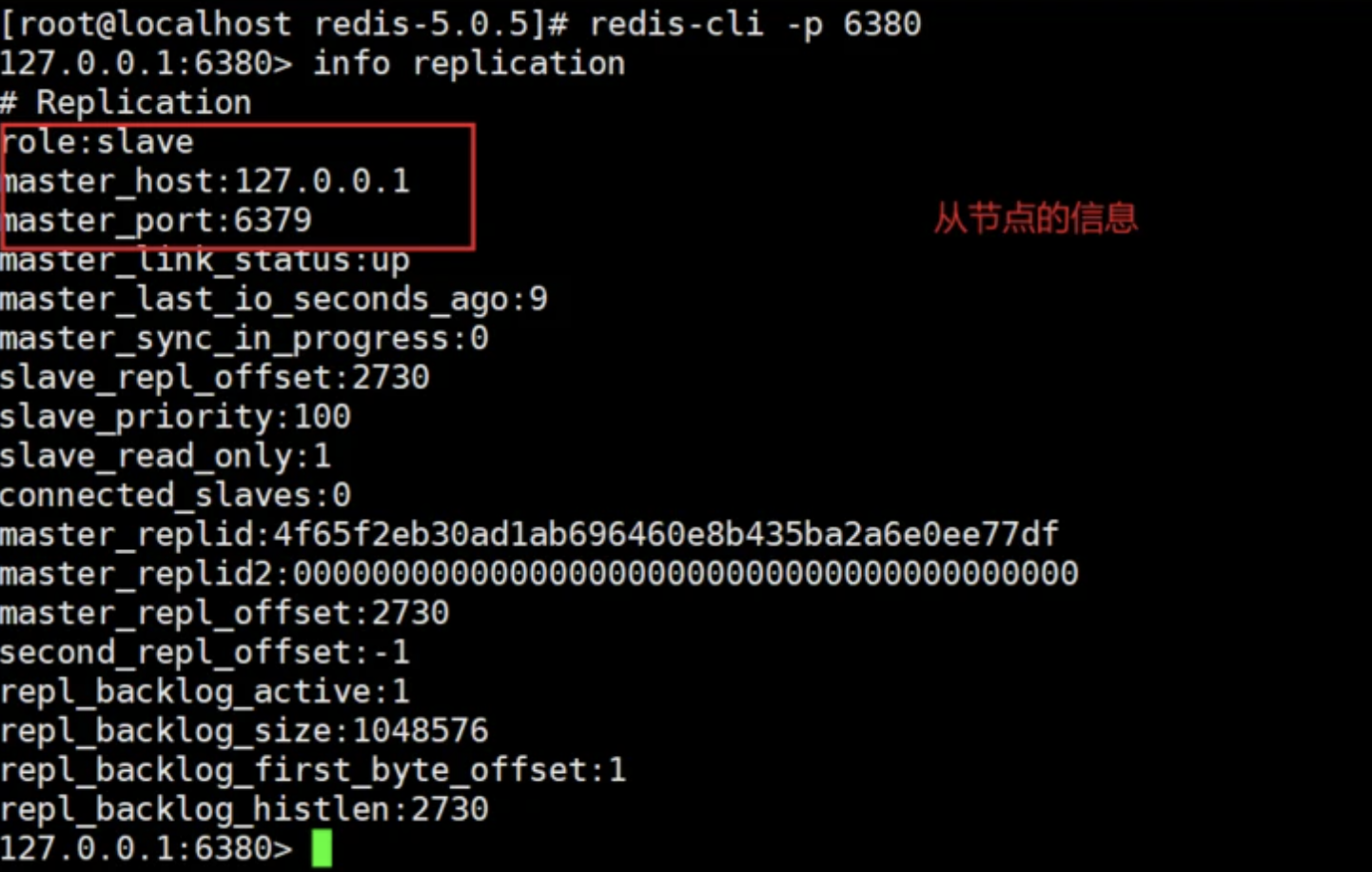
数据同步验证
在 master 节点设置值,在 slave1/slave2 节点可以查看数据同步情况
1 | # master |
主从集成
springboot 中整合 Redis 非常简单,在 pom.xml 中添加依赖
1 | <dependency> |
springboot 2 的spring-boot-starter-data-redis中,默认使用的是 lettuce 作为 redis 客户端,它与 jedis 的主要区别如下:
- Jedis 是同步的,不支持异步,Jedis 客户端实例不是线程安全的,需要每个线程一个 Jedis 实例,所以一般通过连接池来使用 Jedis
- Lettuce 是基于 Netty 框架的事件驱动的 Redis 客户端,其方法调用是异步的,Lettuce 的 API 也是线程安全的,所以多个线程可以操作单个 Lettuce 连接来完成各种操作,同时 Lettuce 也支持连接池
如果不使用默认的 Lettuce,使用 jedis 的话,可以排除 lettuce 的依赖,手动加入 jedis 依赖,配置如下
1 | <dependency> |
在配置文件 application.yml 中添加配置(针对单实例)
1 | spring: |
然后添加配置类。其中 @EnableCaching 注解是为了使 @Cacheable、@CacheEvict、@CachePut、@Caching 注解生效
1 |
|
上述配置类注入了自定义的 RedisTemplate<String, Object>, 替换 RedisAutoConfiguration 中自动配置的 RedisTemplate<Object, Object> 类(RedisAutoConfiguration 另外还自动配置了 StringRedisTemplate)。
此时,我们可以通过定义一个基于 RedisTemplate 的工具类,或通过在 Service 层添加 @Cacheable、@CacheEvict、@CachePut、@Caching 注解来使用缓存。比如定义一个 RedisService 类,封装常用的 Redis 操作方法,
1 |
|
出于篇幅,完整代码请查阅本文示例源码: https://github.com/ronwxy/spr…
或在 Service 层使用注解,如
1 |
|
八、哨兵模式
哨兵模式是一种特殊的模式,首先 Redis 提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例。
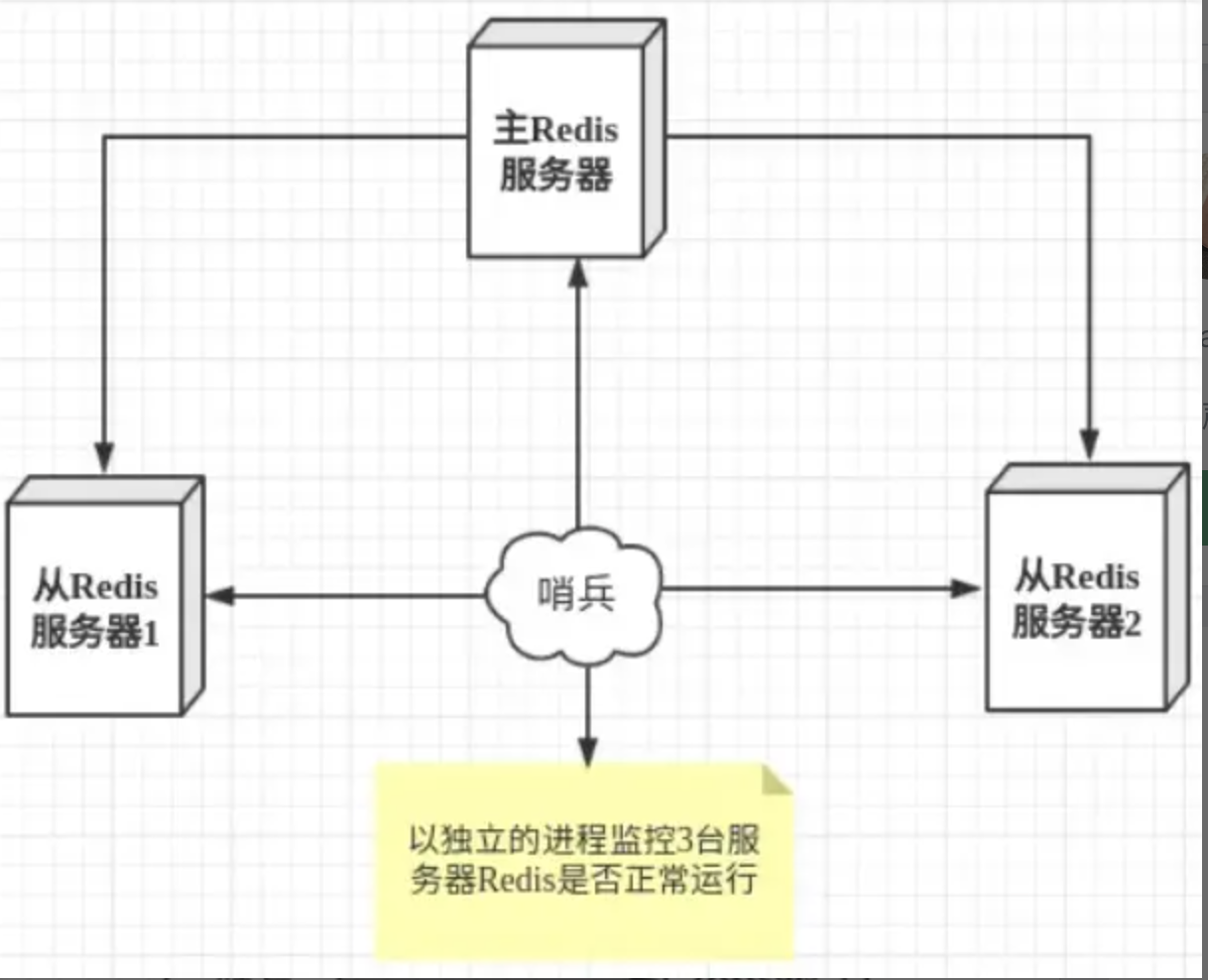
哨兵模式的作用
- 通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器;
- 当哨兵监测到 master 宕机,会自动将 slave 切换成 master ,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机;
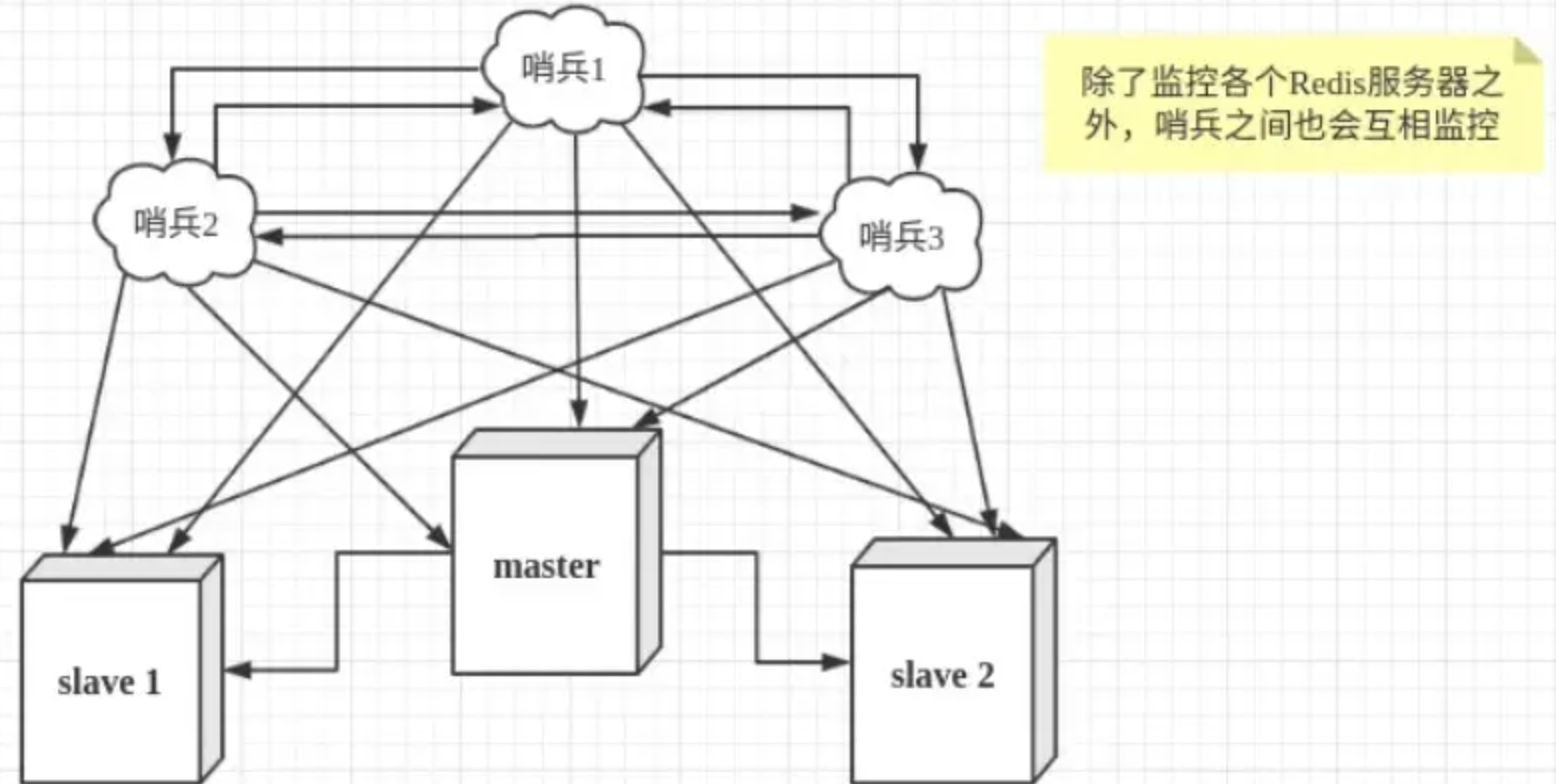
然而一个哨兵进程对Redis服务器进行监控,也可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
故障切换的过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover 操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
哨兵模式的工作方式
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的 Master 主服务器,Slave 从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 如果一个 Master 主服务器被标记为主观下线(SDOWN),则正在监视这个 Master 主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认 Master 主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认 Master 主服务器进入了主观下线状态(SDOWN), 则 Master 主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有 Master 主服务器、Slave 从服务器发送 INFO 命令。
- 当 Master 主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master 主服务器的所有 Slave 从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master 主服务器的客观下线状态就会被移除。若 Master 主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
哨兵模式的优缺点
优点:
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从可以自动切换,系统更健壮,可用性更高(可以看作自动版的主从复制)。
缺点:
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
哨兵配置
主要有两步:
- 准备主从复制集群,并启动
- 增加哨兵配置,启动验证
节点规划
一般来说,哨兵模式的集群是:一主,二从,三哨兵。
那就演示一下三个哨兵的集群。
| 节点 | 配置 | 端口 |
|---|---|---|
| master | redis6379.conf | 6379 |
| slave1 | redis6380.conf | 6380 |
| slave2 | redis6381.conf | 6381 |
| sentinel1 | sentinel1.conf | 26379 |
| sentinel2 | sentinel2.conf | 26380 |
| sentinel3 | sentinel3.conf | 26381 |
哨兵配置
哨兵的配置其实跟 redis.conf 有点像,可以看一下自带的 sentinel.conf
这里创建三个哨兵文件, 哨兵文件的区别在于启动端口不同
1 | # 文件内容 |
启动哨兵
先把 master-slave 启动!
然后,顺序启动三个节点
1 | redis-sentinel sentinel1.conf |
启动之后日志如下,可以看到监听到的主/从节点情况以及哨兵集群情况
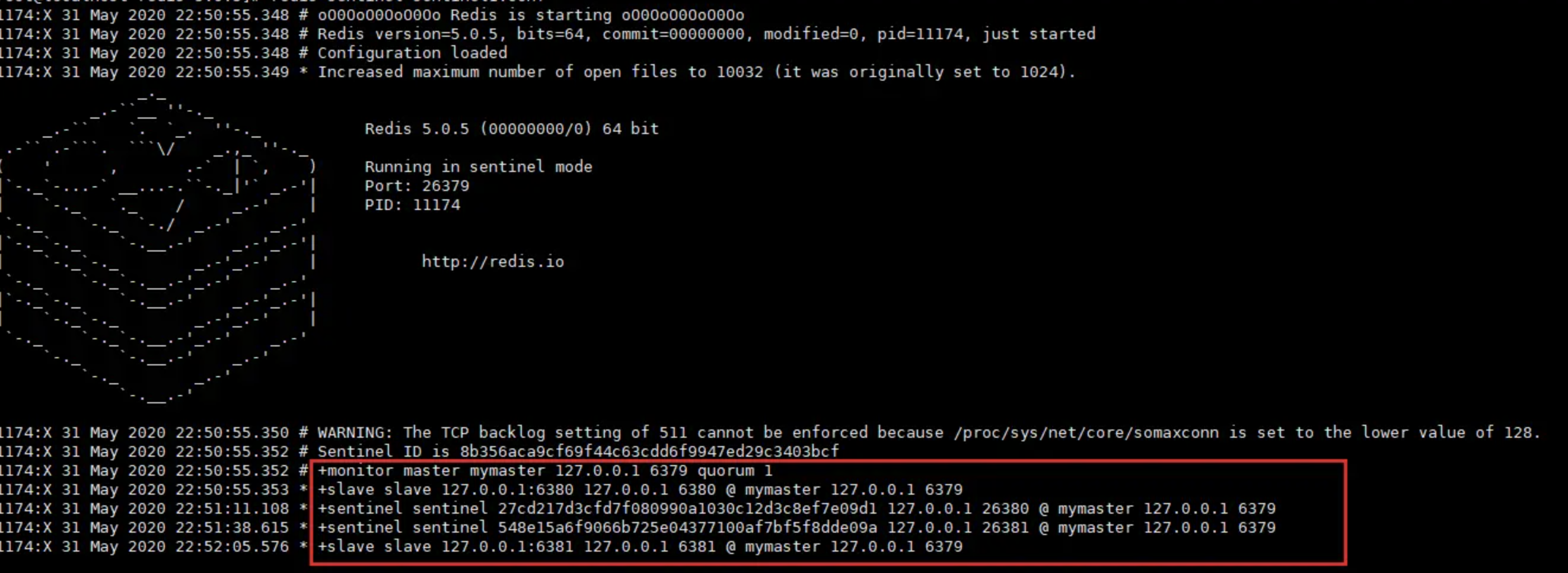
主节点下线模拟
我们在 master(6379) 节点 执行 shutdown,然后观察哨兵会帮我做什么?
可以看到哨兵扫描到了 master 下线, 然后经过一系列判断,投票等操作重新选举了master(6381) 节点
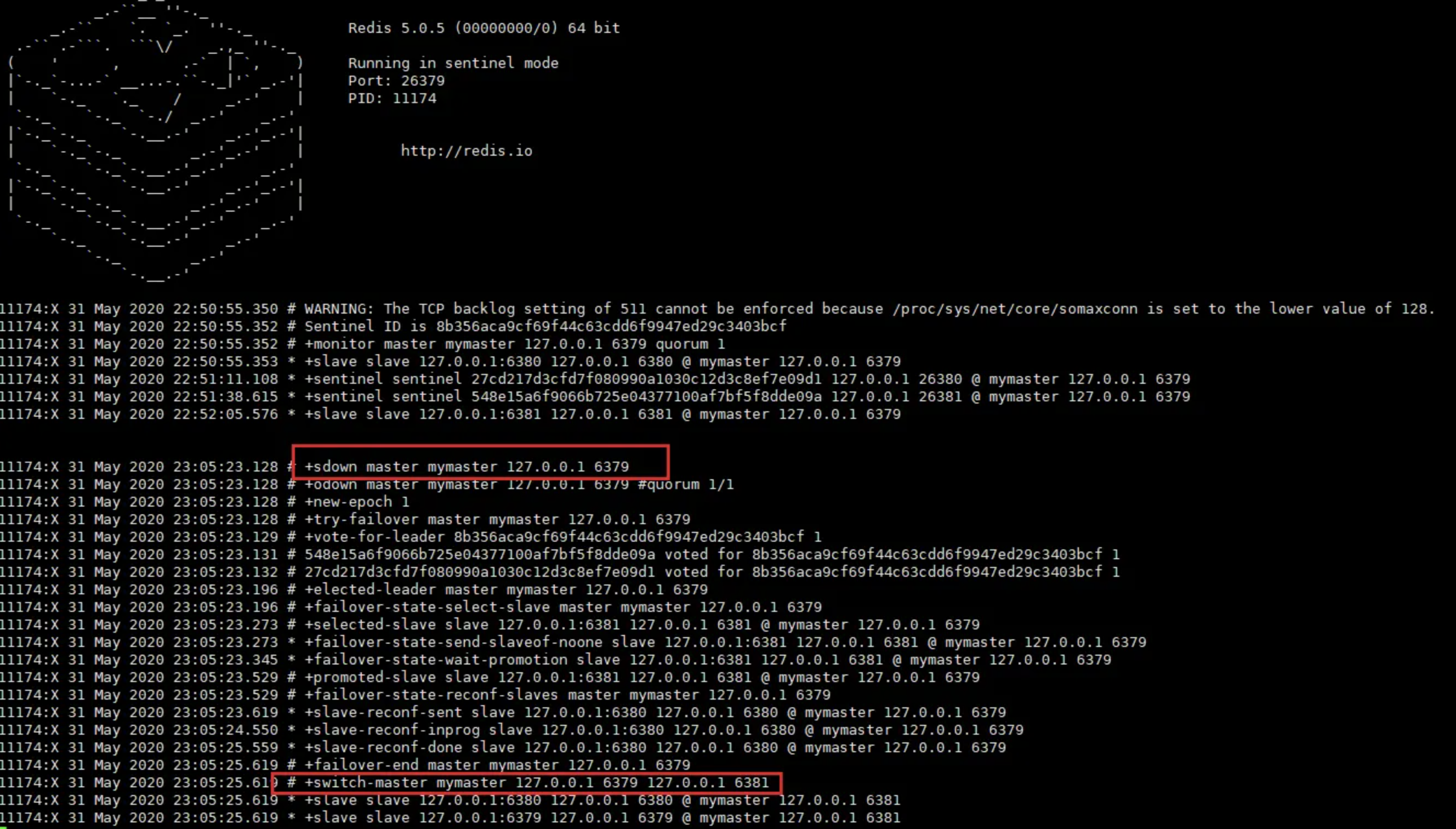
可以查看到,6381 已成为 master
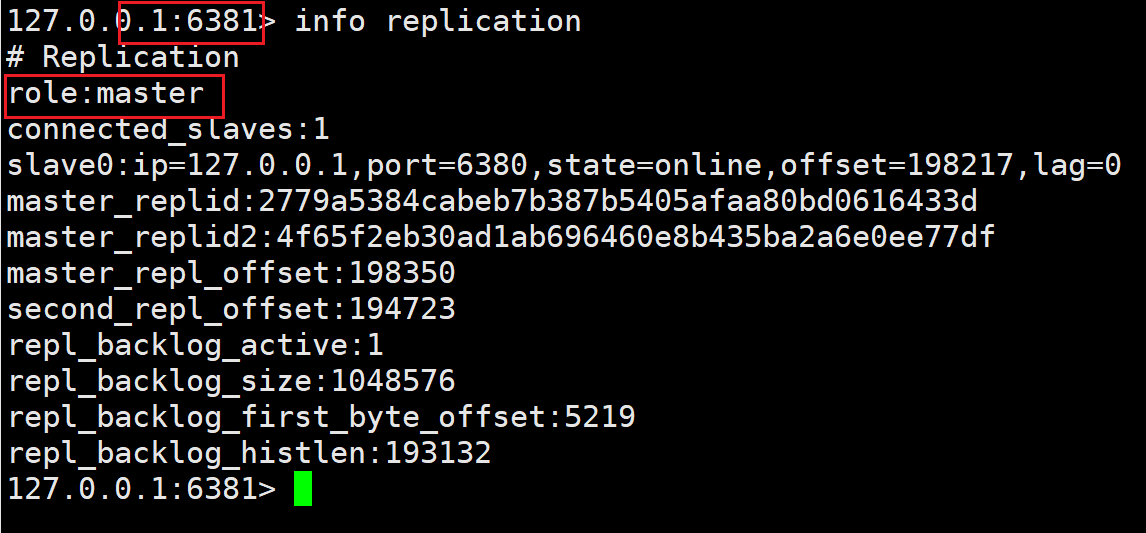
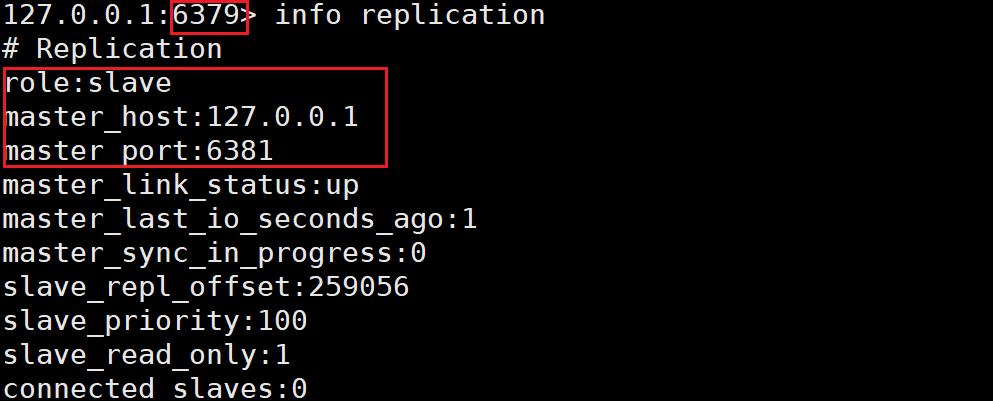
然后我们可以看到, 即使我们把原 master 节点恢复运行, 它也只是 slave 身份了存在了, 失去了大哥的身份, 可谓是风水轮流转了
哨兵集成
Spring Boot 2 整合 Redis 哨兵模式除了配置稍有差异,其它与整合单实例模式类似,配置示例为
1 | spring: |
完整示例可查阅源码: https://github.com/ronwxy/spr…
上述配置只指定了哨兵节点的地址与 master 的名称,但 Redis 客户端最终访问操作的是 master 节点,那么 Redis 客户端是如何获取 master 节点的地址,并在发生故障转移时,如何自动切换 master 地址的呢?我们以 Jedis 连接池为例,通过源码来揭开其内部实现的神秘面纱。
在 JedisSentinelPool 类的构造函数中,对连接池做了初始化,如下
1 | public JedisSentinelPool(String masterName, Set<String> sentinels, |
initSentinels 方法中主要干了两件事:
- 遍历哨兵节点,通过
get-master-addr-by-name命令获取 master 节点的地址信息,找到了就退出循环。get-master-addr-by-name命令执行结果如下所示
1 | [root@dev-server-1 master-slave]# redis-cli -p 26379 |
- 对每一个哨兵节点通过一个 MasterListener 进行监听(Redis 的发布订阅功能),订阅哨兵节点
+switch-master频道,当发生故障转移时,客户端能收到哨兵的通知,通过重新初始化连接池,完成主节点的切换。
MasterListener.run方法中监听哨兵部分代码如下
1 | j.subscribe(new JedisPubSub() { |
initPool 方法如下:如果发现新的 master 节点与当前的 master 不同,则重新初始化。
1 | private void initPool(HostAndPort master) { |
通过以上两步,Jedis 客户端在只知道哨兵地址的情况下便能获得 master 节点的地址信息,并且当发生故障转移时能自动切换到新的 master 节点地址。
九、集群 Cluster
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在 redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容。
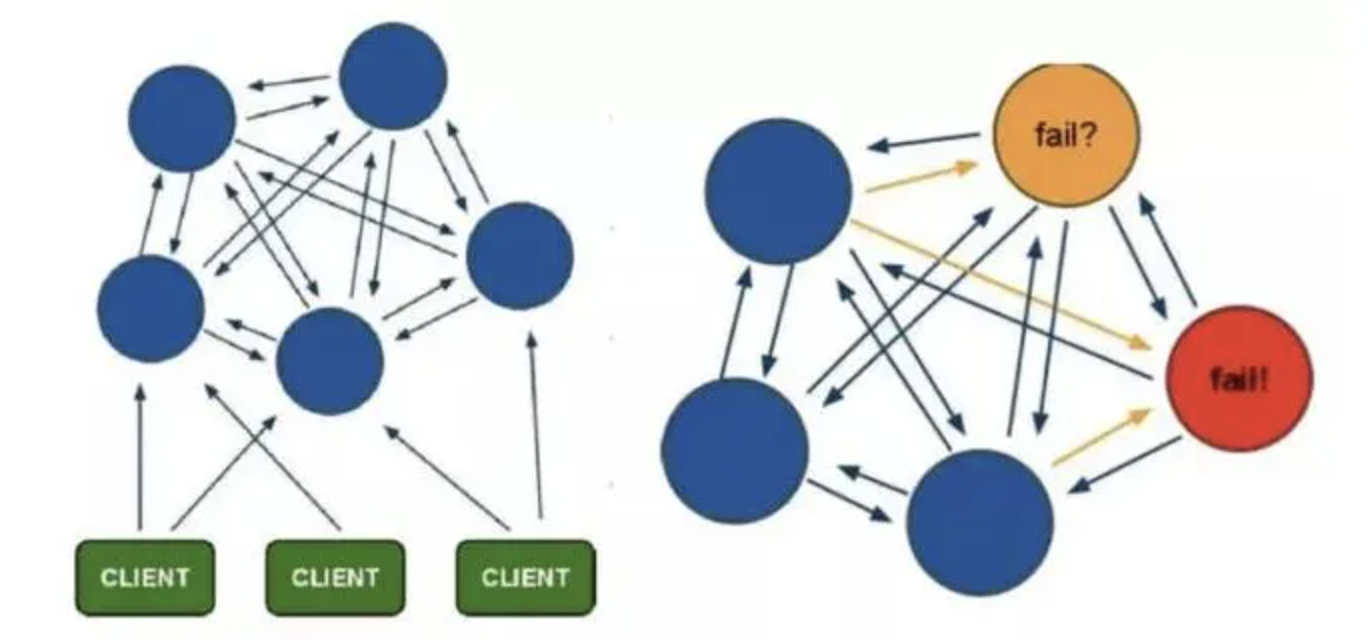
在这个图中,每一个蓝色的圈都代表着一个 redis 的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。
Cluster采用无中心结构,它的特点如下:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测失效时才生效
- 客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
Cluster 模式的具体工作机制
Redis 集群没有使用一致性 hash,而是引入了哈希槽【hash slot】的概念。
- 在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
- 当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- 为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
- 当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster 模式的数据分片
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是 cluster,可以理解为是一个集群管理的插件。当我们的存取的 Key到达的时候,Redis 会根据 CRC16 的算法得出一个结果,然后把结果对 16384 求模,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
Cluster 模式的动态增删节点
举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5460 号哈希槽
- 节点 B 包含 5461 到 10922 号哈希槽
- 节点 C 包含 10923 到 16383 号哈希槽
这种结构很容易添加或者删除节点。比如如果我想新添加个节点 D , 我需要从节点 A, B, C 中得部分槽到 D 上。如果我想移除节点 A ,需要将 A 中的槽移到 B 和 C 节点上,然后将没有任何槽的 A 节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
Redis Cluster 的故障转移
1. 故障发现
当集群内某个节点出现问题时,需要通过一种健壮的方式保证识别出节点是否发生了故障。Redis 集群内节点通过 ping/pong 消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(PFAIL-Possibly Fail)和客观下线(Fail)
- 主观下线:指某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
- 客观下线:指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。所以集群还得经过一次协商的过程,只有当大多数节点都认定了某个节点失联了,集群才认为该节点需要进行主从切换来容错。Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了(PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
1.1 主观下线
集群中每个节点都会定期向其他节点发送 ping 消息,接收节点回复 pong 消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(PFail)状态
- 节点 a 发送 ping 消息给节点b,如果通信正常将接收到 pong 消息,节点a更新最近一次与节点b的通信时间。
- 如果节点 a 与节点 b 通信出现问题则断开连接,下次会进行重连。如果一直通信失败,则节点 a 记录的与节点 b 最后通信时间将无法更新。
- 节点 a 内的定时任务检测到与节点 b 最后通信时间超过
cluster-node-timeout时,更新本地对节点b的状态为主观下线(pfail)。
主观下线简单来讲就是,当cluster-note-timeout时间内某节点无法与另一个节点顺利完成 ping 消息通信时,则将该节点标记为主观下线状态
1.2 客观下线
Redis 集群对于节点最终是否故障判断非常严谨,只有一个节点认为主观下线并不能准确判断是否故障。当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播,通过 Gossip 消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流 程。
==为什么必须是负责槽的主节点参与故障发现决策?==
因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护,而从节点只进行主节点数据和状态信息的复制。
==为什么半数以上处理槽的主节点?==
必须半数以上是为了应对网络分区等原因造成的集群分割情况,被分割的小集群因为无法完成从主观下线到 客观下线这一关键过程,从而防止小集群完成故障转移之后继续对外提供服务。
客观下线流程:
- 当消息体内含有其他节点的 pfail 状态会判断发送节点的状态,如果发送节点是主节点则对报告的 pfail 状态处理,从节点则忽略。
- 找到 pfail 对应的节点,更新其内部下线报告(其中记录了每个节点对该节点做出的下线判断)
- 根据更新后的下线报告链表告尝试进行客观下线
- 每个节点都维护一个都下线报告,保存了其他主节点针对当前节点的下线报告
- 下线报告中保存了报告故障的节点和最近收到下线报告的时间
- 每个下线报告都存在有效期,每次在尝试触发客观下线时,都会检测下线报告是否过期,对于过期的下线报告将被删除。如果在
cluster-node-time*2的时间内该下线报告没有得到更新则过期并删除 - 下线报告的有效期限是
cluster_node_timeout*2,主要是针对故障误报的情况。例如节点 A 在上一小时报告节点 B 主观下线,但是之后又恢复正常。现在又有其他节点上报节点B主观下线,根据实际情况之前的属于误 报不能被使用 - 统计有效的下线报告数量,如果小于集群内持有槽的主节点总数的一半则退出。
- 当下线报告大于槽主节点数量一半时,标记对应故障节点为客观下线状态。
- 向集群广播一条fail消息,通知所有的节点将故障节点标记为客观下线,fail消息的消息体只包含故障节点的 ID
注意:
如果在cluster-node-time*2时间内无法收集到一半以上槽节点的下线报告,那么之前的下线报告将会过期,也就是说主观下线上报的速度追赶不上下线报告过期的速度,那么故障节点将永远无法被标记为客观下线从而导致 故障转移失败。因此不建议将cluster-node-time设置得过小
广播 fail 消息是客观下线的最后一步,它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效。
- 通知故障节点的从节点触发故障转移流程。
需要理解的是,尽管存在广播fail消息机制,但是集群所有节点知道故障节点进入客观下线状态是不确定的。比如当出现网络分区时有可能集群被分割为一大一小两个独立集群中。大的集群持有半数槽节点可以完成客观下线并广播 fail 消息,但是小集群无法接收到 fail 消息,网络分区会导致分割后的小集群无法收到大集群的 fail 消息,因此如果故障节点所有的从节点都在小集群内将导致无法完成后续故障转移,因此部署主从结构时需要根据自身机房/机架拓扑结构,降低主从被分区的可能性。
2. 故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程
每个从节点都要检查最后与主节点断线时间,判断是否有资格替换故障的主节点。如果从节点与主节点断线时间超过
cluster-node-time*cluster-slave-validity-factor,则当前从节点不具备故障转移资格,cluster-slave-validity-factor设置为 0 代表任何 slave 都可以被转换为 master,默认为 10当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程,这里之所以采用延迟触发机制,主要是通过对多个从节点使用不同的延迟选举时间来支持优先级问题。复制偏移量越大说明从节点延迟越低,那么它应该具有更高的优先级来替换故障主节点,所有的从节点中复制偏移量最大的将提前触发故障选举流程
当从节点定时任务检测到达故障选举时间 (failover_auth_time) 到达后,发起选举流程
更新配置版本 配置纪元是一个只增不减的整数,每个主节点自身维护一个配置版本 (clusterNode.configEpoch) 标示当前主节点的版本,所有主节点的配置版本都不相等,从节点会复制主节点的配置版本。整个集群又维护一个全局的配置版本 (clusterState.current Epoch) ,用于记录集群内所有主节点配置版本的最大版本。执行
1
cluster info
命令可以查看配置版本信息 10.0.0.102:6379> cluster info cluster_current_epoch:6 cluster_my_epoch:4 配置版本会跟随 ping/pong 消息在集群内传播,当发送方与接收方都是主节点且配置版本相等时代表出现了冲突,nodeId 更大的一方会递增全局配置版本并赋值给当前节点来区分冲突 配置版本的主要作用:
- 标示集群内每个主节点的不同版本和当前集群最大的版本
- 每次集群发生重要事件时,这里的重要事件指出现新的主节点(新加入的或者由从节点转换而来),从节点竞争选举。都会递增集群全局的配置版本并赋值给相关主节点,用于记录这一关键事件。
- 主节点具有更大的配置版本代表了更新的集群状态,因此当节点间进行 ping/pong 消息交换时,如出现 slots 等关键信息不一致时,以配置版本更大的一方为准,防止过时的消息状态污染集群。
- 配置版本的应用场景有: 新节点加入 槽节点映射冲突检测 从节点投票选举冲突检测
- 在通过`cluster setslot`命令修改槽节点映射时,需要确保执行请求的主节点本地配置版本是最大值,否则修改后的槽信息在消息传播中不会被拥有更高的配置版本的节点采纳。由于 Gossip 通信机制无法准确知道当前最大的配置版本在哪个节点,因此在槽迁移任务最后的`cluster setslot {slot} node {nodeId}`命令需要在全部主节点中执行一遍。
- 从节点每次发起投票时都会自增集群的全局配置版本,并单独保存`clusterState.failover_auth_epoch`变量中用于标识本次从节点发起选举的版本
广播选举消息 在集群内广播选举消息
FAILOVER_AUTH_REQUEST,并记录已发送过消息的状态,保证该从节点在一个配置版本内只能发起一次选举选举投票 只有持有槽的主节点才会处理故障选举消息
FAILOVER_AUTH_REQUEST,因为每个持有槽的节点在一个配置版本内都有唯一的一张选票,当接到第一个请求投票的从节点消息时回复FAILOVER_AUTH_ACK消息作为投票,之后相同配置版本内其他从节点的选举消息将忽略 投票过程其实是一个领导者选举的过程,如集群内有 N 个持有槽的主节点代表有 N 张选票。由于在每个配置版本内持有槽的主节点只能投票给一个从节点,因此只能有一个从节点获得 N/2+1 的选票,保证能够找出唯一的从节点。 Redis 集群没有直接使用从节点进行领导者选举(投票让支持槽节点的 master 来做,而不是多个 slave 之间的投票),主要因为从节点数必须大于等于 3 个才能保证凑够 N/2+1 个节点,将导致从节点资源浪费。使用集群内所有持有槽的主节点进行领导者选举,即使只有一个从节点也可以完成选举过程。 当从节点收集到 N/2+1 个持有槽的主节点投票时,从节点可以执行替换主节点操作,例如集群内有 5 个持有槽的主节点,主节点b故障后还有 4 个,当其中一个从节点收集到 3 张投票时代表获得了足够的选票可以进行替换主节点操作 故障主节点也算在投票数内,假设集群内节点规模是 3 主 3 从,其中有 2 个主节点部署在一台机器上,当这台机器宕机时,由于从节点无法收集到 3/2+1 个主节点选票将导致故障转移失败。这个问题也适用于故障发现环节。因此部署集群时所有主节点最少需要部署在 3 台物理机上才能避免单点问题。 投票作废:每个配置版本代表了一次选举周期,如果在开始投票之后的cluster-node-timeout*2时间内从节点没有获取足够数量的投票,则本次选举作废。其他从节点对配置版本自增并发起下一轮投票,直到选举成功为止 Redis Cluster 可以为每个主节点设置若干个从节点,单主节点故障时,集群会自动将其中某个从节点提升为主节点。如果某个主节点没有从节点,那么当它发生故障时,集群将完全处于不可用状态。不过 Redis 也提供了一个参数cluster-require-full-coverage(默认yes)可以允许部分节点故障,其它节点还可以继续提供对外访问。替换主节点 当从节点收集到足够的选票之后,触发替换主节点操作:
当前从节点取消复制变为主节点。
执行 clusterDelSlot 操作撤销故障主节点负责的槽,并执行 clusterAddSlot 把这些槽委派给自己
向集群广播自己的 pong 消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
3. 故障转移时间
- 主观下线 (pfail) 识别时间 =
cluster-node-timeout - 主观下线状态消息传播时间 <=
cluster-node-timeout/2,消息通信机制对超过cluster-node-timeout/2未通信节点会发起 ping 消息,消息体在选择包含哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数以上主节点的 pfail 报告从而完成故障发现 - 从节点转移时间 <=1000 毫秒,由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟1秒发起选举。通常第一次选举就会成功,所以从节点执行转移时间在 1 秒以内
- 根据以上分析可以预估出故障转移时间:
failover-time ≤ (cluster-node-timeout * 1.5 + 1000)ms,因此,故障转移时间跟cluster-node-timeout参数息息相关,默认 15 秒,配置时可以根据业务容忍度做出适当调整,但不是越小越好
为了保证高可用,redis-cluster 集群引入了主从复制模型,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点 ping 一个主节点 A 时,如果半数以上的主节点与 A 通信超时,那么认为主节点 A 宕机了。如果主节点 A 和它的从节点 A1 都宕机了,那么该集群就无法再提供服务了。
Cluster 模式集群节点最小配置 6 个节点( 3 主 3 从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
4. 故障转移演练
- 一个 master 下线
1 | root 3423 1 0 11:38 ? 00:01:06 bin/redis-server 10.0.0.100:6379 [cluster] |
- slave 与下线 master 的主从复制中断
1 | [root@node03 redis]# cat /var/log/redis/redis_6380.log |
- 其他两个 master 标记下线 master 主观下线
1 | [root@node02 redis]# cat /var/log/redis/redis_6379.log |
- 超半数 master 认为下线 master 主观下线,所以下线 master 客观下线
- slave 节点在延迟 724ms 后,开始准备选举,它和下线 master 的复制偏移量是 21930
1 | 2654:S 25 Mar 17:10:45.415 # Cluster state changed: fail |
- slave 更新配置版本并发起选举
1 | 2654:S 25 Mar 17:10:46.322 # Starting a failover election for epoch 7. |
- 其他两个 master 对 slave 进行了投票
1 | 2649:M 25 Mar 17:10:46.327 # Failover auth granted to 0955dc1eeeec59c1e9b72eca5bcbcd04af108820 for epoch 7 |
- 重启下线的 master
1 | [root@node01 redis]# bin/redis-server conf/redis_6379.conf |
- 旧 master 节点启动后发现自己负责的槽指派给另一个节点,则以现有集群配置为准,变为新主节点的从节点
1 | 3873:M 25 Mar 17:24:32.823 * Node configuration loaded, I'm 9c02aef2d45e44678202721ac923c615dd8300ea |
- 集群内其他节点接收到新上线发来的 ping 消息,清空客观下线状态
1 | 3428:S 25 Mar 17:24:32.830 * Clear FAIL state for node 9c02aef2d45e44678202721ac923c615dd8300ea: master without slots is reachable again. |
- 新的主从开始复制
1 | # slave |
集群的特点
- 所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽。
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效。
- 客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
Cluster 集群模式优缺点
优点
- 无中心架构,数据按照 slot 分布在多个节点。
- 集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
- 可线性扩展到 1000 多个节点,节点可动态添加或删除
- 能够实现自动故障转移,节点之间通过 gossip 协议交换状态信息,用投票机制完成 slave 到 master 的角色转换
缺点
- 客户端实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度。目前仅 JedisCluster 相对成熟,异常处理还不完善,比如常见的 “max redirect exception”
- 节点会因为某些原因发生阻塞(阻塞时间大于 cluster-node-timeout)被判断下线,这种 failover 是没有必要的
- 数据通过异步复制,不保证数据的强一致性
- slave 充当“冷备”,不能缓解读压力
- 批量操作限制,目前只支持具有相同 slot 值的 key 执行批量操作,对 mset、mget、sunion 等操作支持不友好
- key 事务操作支持有线,只支持多 key 在同一节点的事务操作,多 key 分布不同节点时无法使用事务功能
- 不支持多数据库空间,单机 redis 可以支持 16 个 db,集群模式下只能使用一个,即 db 0
Redis Cluster 模式不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
集群配置
主要有两步
- 配置文件
- 启动验证
节点规划
根据官方推荐,集群部署至少要 3 台以上的 master 节点,最好使用 3 主 3 从六个节点的模式。
| 节点 | 配置 | 端口 |
|---|---|---|
| cluster-master1 | redis7001.conf | 7001 |
| cluster-master2 | redis7002.conf | 7002 |
| cluster-master3 | redis7003.conf | 7003 |
| cluster-slave1 | redis7004.conf | 7004 |
| cluster-slave2 | redis7006.conf | 7005 |
| cluster-slave3 | redis7006.conf | 7006 |
集群配置
咱们准备 6 个配置文件 ,端口 7001,7002,7003,7004,7005,7006
分别命名成 redis7001.conf ……redis7006.conf
redis7001.conf 配置文件内容如下(记得复制6份并替换端口号)
1 | 端口 |
启动 redis 节点
- 挨个启动节点
1 | redis-server redis7001.conf |
以下启动情况

启动集群
1 | 执行命令 |
数据验证
1 | 注意 集群模式下要带参数 -c,表示集群,否则不能正常存取数据!!! |
集群集成
Spring Boot 2 整合 Redis Cluster 模式除了配置稍有差异,其它与整合单实例模式也类似,配置示例为
1 | spring: |
完整示例可查阅源码: https://github.com/ronwxy/spr…
在上文中已经介绍了 Cluster 模式访问的基本原理,可以通过任意节点跳转到目标节点执行命令,上面配置中 max-redirects 控制在集群中跳转的最大次数。
查看JedisClusterConnection.execute方法,
1 | public Object execute(String command, byte[]... args) { |
集群命令的执行是通过ClusterCommandExecutor.executeCommandOnArbitraryNode来实现的,
1 | public <T> NodeResult<T> executeCommandOnArbitraryNode(ClusterCommandCallback<?, T> cmd) { |
上述代码逻辑如下
- 从集群节点列表中随机选择一个节点
- 从该节点获取一个客户端连接(如果配置了连接池,从连接池中获取),执行命令
- 如果抛出
ClusterRedirectException异常,则跳转到返回的目标节点上执行 - 如果跳转次数大于配置的值 max-redirects, 则抛出
TooManyClusterRedirectionsException异常
可能遇到的问题
- Redis连接超时
检查服务是否正常启动(比如 ps -ef|grep redis查看进程,netstat -ano|grep 6379查看端口是否起来,以及日志文件),如果正常启动,则查看Redis服务器是否开启防火墙,关闭防火墙或配置通行端口。
- Cluster模式下,报连接到127.0.0.1被拒绝错误,如
Connection refused: no further information: /127.0.0.1:7600
这是因为在redis.conf中配置 bind 0.0.0.0 或 bind 127.0.0.1导致,需要改为具体在外部可访问的IP,如 bind 192.168.40.201。如果之前已经起了集群,并产生了数据,则修改redis.conf文件后,还需要修改cluster-config-file文件,将127.0.0.1替换为bind 的具体IP,然后重启。
- master挂了,slave升级成为master,重启master,不能正常同步新的master数据
如果设置了密码,需要在master, slave的配置文件中都配置masterauth password
十、常见问题
缓存穿透、缓存击穿、缓存雪崩、缓存预热、缓存降级
缓存穿透
问题描述:缓存穿透是指用户==请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在==,导致用户每次请求该数据都要去数据库中查询一遍。如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至导致数据库承受不住而宕机崩溃。
问题分析:缓存穿透的关键在于在Redis中查不到key值,它和缓存击穿的根本区别在于传进来的key在Redis中是不存在的。假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题,所以在日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误提示。
解决方案:
将无效的key存放进Redis中:
当出现Redis查不到数据,数据库也查不到数据的情况,我们就把这个key保存到Redis中,设置value=”null”,并设置其过期时间极短,后面再出现查询这个key的请求的时候,直接返回null,就不需要再查询数据库了。但这种处理方式是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。使用布隆过滤器:
如果布隆过滤器判定某个 key 不存在布隆过滤器中,那么就一定不存在,如果判定某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一个布隆过滤器,将数据库中的所有key都存储在布隆过滤器中,在查询Redis前先去布隆过滤器查询 key 是否存在,如果不存在就直接返回,不让其访问数据库,从而避免了对底层存储系统的查询压力。
如何选择:针对一些恶意攻击,攻击带过来的大量key是随机,那么我们采用第一种方案就会缓存大量不存在key的数据。那么这种方案就不合适了,我们可以先对使用布隆过滤器方案进行过滤掉这些key。所以,针对这种key异常多、请求重复率比较低的数据,优先使用第二种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,则可优先采用第一种方式进行缓存。
缓存击穿
- 问题描述:缓存击穿跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而==缓存击穿是某个热点的key失效==,大并发集中对其进行请求,就会造成大量请求读缓存没读到数据,从而导致高并发访问数据库,引起数据库压力剧增。这种现象就叫做缓存击穿。
- 问题分析:关键在于某个热点的key失效了,导致大并发集中打在数据库上。所以要从两个方面解决,第一是否可以考虑热点key不设置过期时间,第二是否可以考虑降低打在数据库上的请求数量。
- 解决方案:
- 在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
- 热点数据缓存永远不过期。
永不过期实际包含两层意思:
物理不过期,针对热点key不设置过期时间
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
缓存雪崩
问题描述:如果==缓存在某一个时刻出现大规模的key失效==,那么就会导致大量的请求打在了数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
问题分析:造成缓存雪崩的关键在于同一时间的大规模的key失效,主要有两种可能:第一种是Redis宕机,第二种可能就是采用了相同的过期时间。
解决方案:
事前:
- 均匀过期:设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致缓存雪崩,造成大量数据库的访问。
- 分级缓存:第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
- 热点数据缓存永远不过期。
- 保证Redis缓存的高可用,防止Redis宕机导致缓存雪崩的问题。可以使用 主从+ 哨兵,Redis集群来避免 Redis 全盘崩溃的情况。
事中:
- 互斥锁:在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
- 使用熔断机制,限流降级。当流量达到一定的阈值,直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上将数据库击垮,至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
事后:
- 开启Redis持久化机制,尽快恢复缓存数据,一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
缓存预热
- 问题描述:缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
- 问题分析:如果不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
- 解决方案:
- 数据量不大的时候,工程启动的时候进行加载缓存动作。
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新。
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
分布式锁的实现
为什么需要分布式锁
与分布式锁相对应的是「单机锁」,我们在写多线程程序时,避免同时操作一个共享变量产生数据问题,通常会使用一把锁来「互斥」,以保证共享变量的正确性,其使用范围是在「同一个进程」中。
如果换做是多个进程,需要同时操作一个共享资源,如何互斥呢?
例如,现在的业务应用通常都是微服务架构,这也意味着一个应用会部署多个进程,那这多个进程如果需要修改 MySQL 中的同一行记录时,为了避免操作乱序导致数据错误,此时,我们就需要引入「分布式锁」来解决这个问题了。
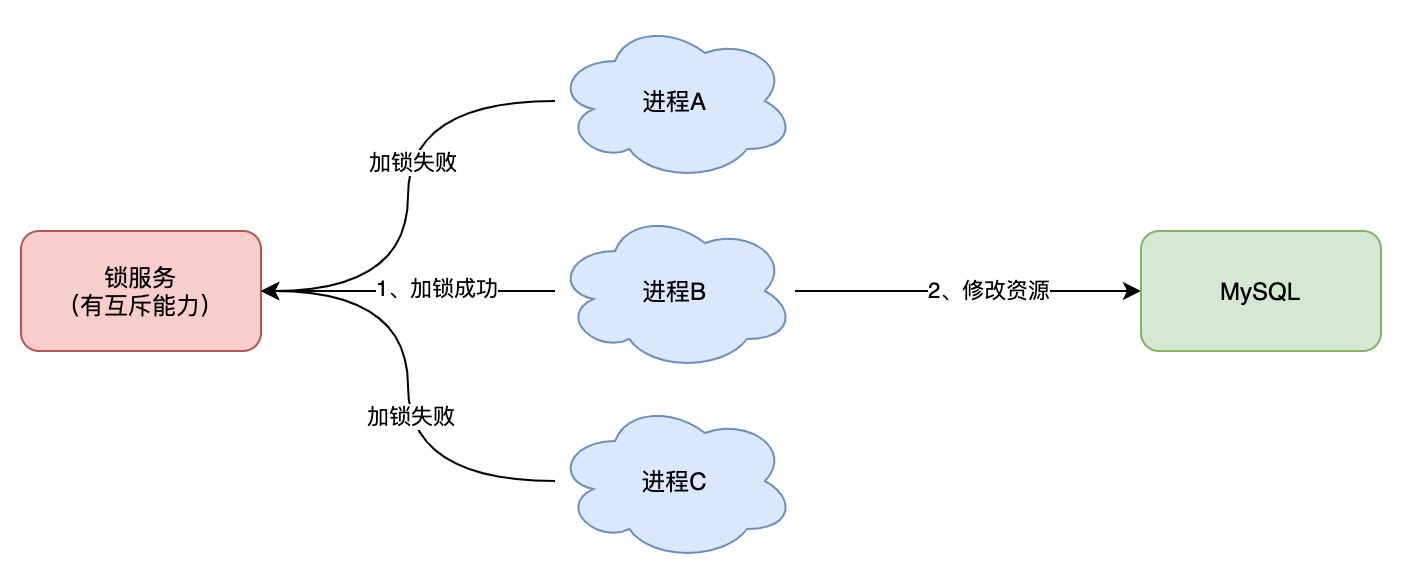
想要实现分布式锁,必须借助一个外部系统,所有进程都去这个系统上申请「加锁」。
而这个外部系统,必须要实现「互斥」的能力,即两个请求同时进来,只会给一个进程返回成功,另一个返回失败(或等待)。
这个外部系统,可以是 MySQL,也可以是 Redis 或 Zookeeper。但为了追求更好的性能,我们通常会选择使用 Redis 或 Zookeeper 来做。
分布式锁如何实现
想要实现分布式锁,必须要求 Redis 有「互斥」的能力,我们可以使用 SETNX 命令,这个命令表示SET if Not eXists,即如果 key 不存在,才会设置它的值,否则什么也不做。
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
客户端 1 申请加锁,加锁成功:
1 | 127.0.0.1:6379> SETNX lock 1 |
客户端 2 申请加锁,因为后到达,加锁失败:
1 | 127.0.0.1:6379> SETNX lock 1 |
此时,加锁成功的客户端,就可以去操作「共享资源」,例如,修改 MySQL 的某一行数据,或者调用一个 API 请求。
操作完成后,还要及时释放锁,给后来者让出操作共享资源的机会。如何释放锁呢?
也很简单,直接使用 DEL 命令删除这个 key 即可:
1 | 127.0.0.1:6379> DEL lock // 释放锁 |
这个逻辑非常简单,整体的路程就是这样:

但是,它存在一个很大的问题,当客户端 1 拿到锁后,如果发生下面的场景,就会造成「死锁」:
- 程序处理业务逻辑异常,没及时释放锁
- 进程挂了,没机会释放锁
这时,这个客户端就会一直占用这个锁,而其它客户端就「永远」拿不到这把锁了。
如何避免死锁
我们很容易想到的方案是,在申请锁时,给这把锁设置一个「租期」。
在 Redis 中实现时,就是给这个 key 设置一个「过期时间」。这里我们假设,操作共享资源的时间不会超过 10s,那么在加锁时,给这个 key 设置 10s 过期即可:
1 | 127.0.0.1:6379> SETNX lock 1 // 加锁 |
这样一来,无论客户端是否异常,这个锁都可以在 10s 后被「自动释放」,其它客户端依旧可以拿到锁。
但这样真的没问题吗?
还是有问题。
现在的操作,加锁、设置过期是 2 条命令,有没有可能只执行了第一条,第二条却「来不及」执行的情况发生呢?例如:
- SETNX 执行成功,执行 EXPIRE 时由于网络问题,执行失败
- SETNX 执行成功,Redis 异常宕机,EXPIRE 没有机会执行
- SETNX 执行成功,客户端异常崩溃,EXPIRE 也没有机会执行
总之,这两条命令不能保证是原子操作(一起成功),就有潜在的风险导致过期时间设置失败,依旧发生「死锁」问题。
怎么办?
在 Redis 2.6.12 版本之前,我们需要想尽办法,保证 SETNX 和 EXPIRE 原子性执行,还要考虑各种异常情况如何处理。
但在 Redis 2.6.12 之后,Redis 扩展了 SET 命令的参数,用这一条命令就可以了:
1 | // 一条命令保证原子性执行 |
这样就解决了死锁问题,也比较简单。
我们再来看分析下,它还有什么问题?
试想这样一种场景:
- 客户端 1 加锁成功,开始操作共享资源
- 客户端 1 操作共享资源的时间,「超过」了锁的过期时间,锁被「自动释放」
- 客户端 2 加锁成功,开始操作共享资源
- 客户端 1 操作共享资源完成,释放锁(但释放的是客户端 2 的锁)
看到了么,这里存在两个严重的问题:
- 锁过期:客户端 1 操作共享资源耗时太久,导致锁被自动释放,之后被客户端 2 持有
- 释放别人的锁:客户端 1 操作共享资源完成后,却又释放了客户端 2 的锁
导致这两个问题的原因是什么?我们一个个来看。
第一个问题,可能是我们评估操作共享资源的时间不准确导致的。
例如,操作共享资源的时间「最慢」可能需要 15s,而我们却只设置了 10s 过期,那这就存在锁提前过期的风险。
过期时间太短,那增大冗余时间,例如设置过期时间为 20s,这样总可以了吧?
这样确实可以「缓解」这个问题,降低出问题的概率,但依旧无法「彻底解决」问题。
为什么?
原因在于,客户端在拿到锁之后,在操作共享资源时,遇到的场景有可能是很复杂的,例如,程序内部发生异常、网络请求超时等等。
既然是「预估」时间,也只能是大致计算,除非你能预料并覆盖到所有导致耗时变长的场景,但这其实很难。
有什么更好的解决方案吗?
别急,关于这个问题,我会在后面详细来讲对应的解决方案。
我们继续来看第二个问题。
第二个问题在于,一个客户端释放了其它客户端持有的锁。
想一下,导致这个问题的关键点在哪?
重点在于,每个客户端在释放锁时,都是「无脑」操作,并没有检查这把锁是否还「归自己持有」,所以就会发生释放别人锁的风险,这样的解锁流程,很不「严谨」!
锁被别人释放怎么办?
解决办法是:客户端在加锁时,设置一个只有自己知道的「唯一标识」进去。
例如,可以是自己的线程 ID,也可以是一个 UUID(随机且唯一),这里我们以 UUID 举例:
1 | // 锁的VALUE设置为UUID |
这里假设 20s 操作共享时间完全足够,先不考虑锁自动过期的问题。
之后,在释放锁时,要先判断这把锁是否还归自己持有,伪代码可以这么写:
1 | // 锁是自己的,才释放 |
这里释放锁使用的是 GET + DEL 两条命令,这时,又会遇到我们前面讲的原子性问题了。
- 客户端 1 执行 GET,判断锁是自己的
- 客户端 2 执行了 SET 命令,强制获取到锁(虽然发生概率比较低,但我们需要严谨地考虑锁的安全性模型)
- 客户端 1 执行 DEL,却释放了客户端 2 的锁
由此可见,这两个命令还是必须要原子执行才行。
怎样原子执行呢?Lua 脚本。
我们可以把这个逻辑,写成 Lua 脚本,让 Redis 来执行。
因为 Redis 处理每一个请求是「单线程」执行的,在执行一个 Lua 脚本时,其它请求必须等待,直到这个 Lua 脚本处理完成,这样一来,GET + DEL 之间就不会插入其它命令了
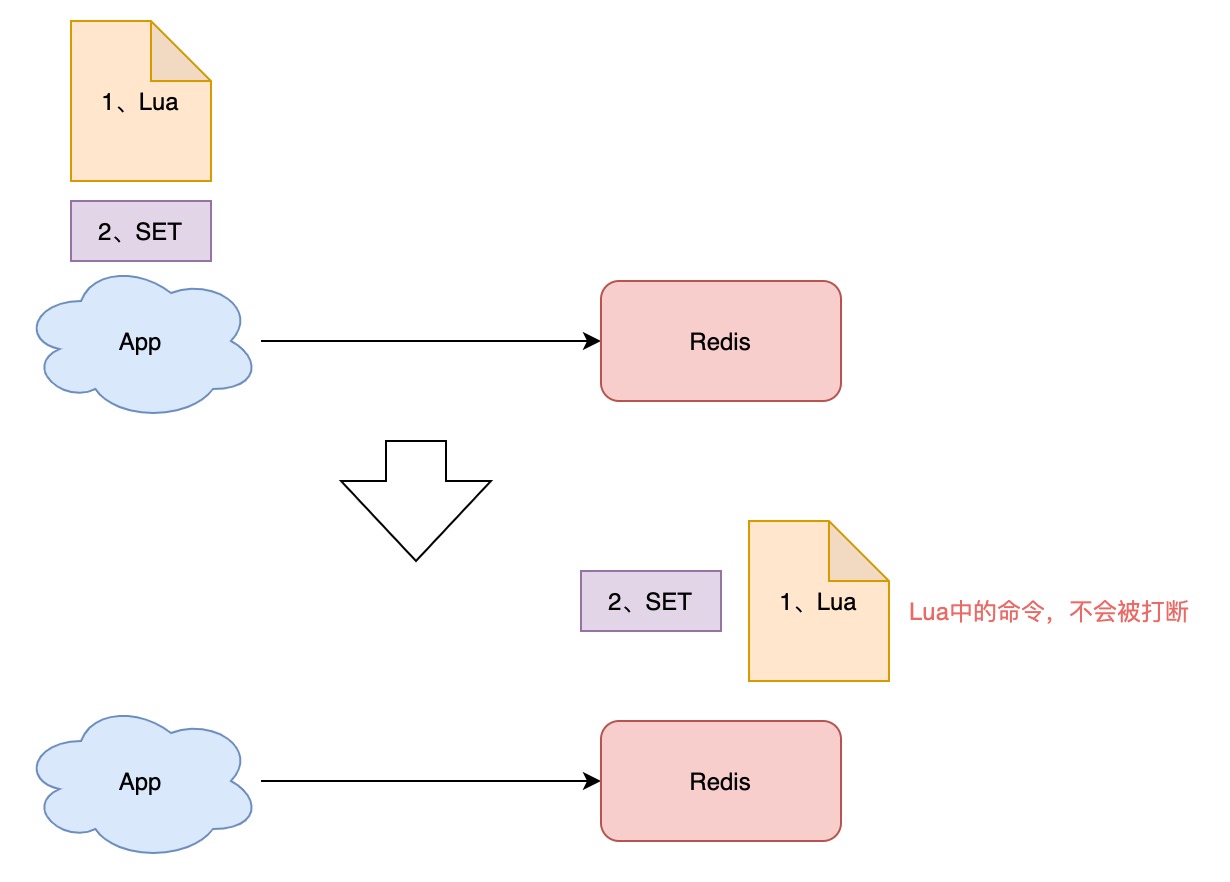
安全释放锁的 Lua 脚本如下:
1 | // 判断锁是自己的,才释放 |
好了,这样一路优化,整个的加锁、解锁的流程就更「严谨」了。
这里我们先小结一下,基于 Redis 实现的分布式锁,一个严谨的的流程如下:
- 加锁:SET $lock_key $unique_id EX $expire_time NX
- 操作共享资源
- 释放锁:Lua 脚本,先 GET 判断锁是否归属自己,再 DEL 释放锁

有了这个完整的锁模型,让我们重新回到前面提到的第一个问题。
锁过期时间不好评估怎么办?
前面我们提到,锁的过期时间如果评估不好,这个锁就会有「提前」过期的风险。
当时给的妥协方案是,尽量「冗余」过期时间,降低锁提前过期的概率。
这个方案其实也不能完美解决问题,那怎么办呢?
是否可以设计这样的方案:加锁时,先设置一个过期时间,然后我们开启一个「守护线程」,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
这确实一种比较好的方案。
如果你是 Java 技术栈,幸运的是,已经有一个库把这些工作都封装好了:Redisson。
Redisson 是一个 Java 语言实现的 Redis SDK 客户端,在使用分布式锁时,它就采用了「自动续期」的方案来避免锁过期,这个守护线程我们一般也把它叫做「看门狗」线程
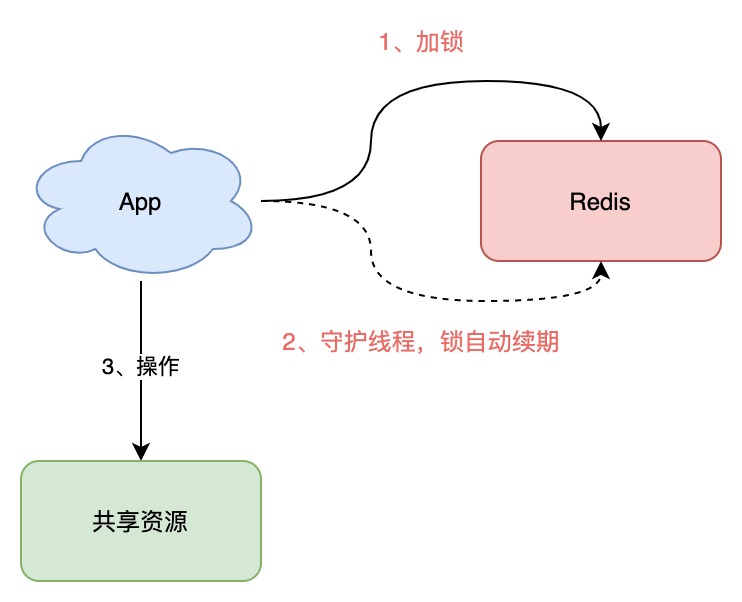
除此之外,这个 SDK 还封装了很多易用的功能:
- 可重入锁
- 乐观锁
- 公平锁
- 读写锁
- Redlock(红锁,下面会详细讲)
这个 SDK 提供的 API 非常友好,它可以像操作本地锁的方式,操作分布式锁。如果你是 Java 技术栈,可以直接把它用起来。
这里不重点介绍 Redisson 的使用,大家可以看官方 Github 学习如何使用,比较简单。
到这里我们再小结一下,基于 Redis 的实现分布式锁,前面遇到的问题,以及对应的解决方案:
- 死锁:设置过期时间
- 过期时间评估不好,锁提前过期:守护线程,自动续期
- 锁被别人释放:锁写入唯一标识,释放锁先检查标识,再释放
还有哪些问题场景,会危害 Redis 锁的安全性呢?
之前分析的场景都是,锁在「单个」Redis 实例中可能产生的问题,并没有涉及到 Redis 的部署架构细节。
而我们在使用 Redis 时,一般会采用主从集群 + 哨兵的模式部署,这样做的好处在于,当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。
那当「主从发生切换」时,这个分布锁会依旧安全吗?
试想这样的场景:
- 客户端 1 在主库上执行 SET 命令,加锁成功
- 此时,主库异常宕机,SET 命令还未同步到从库上(主从复制是异步的)
- 从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
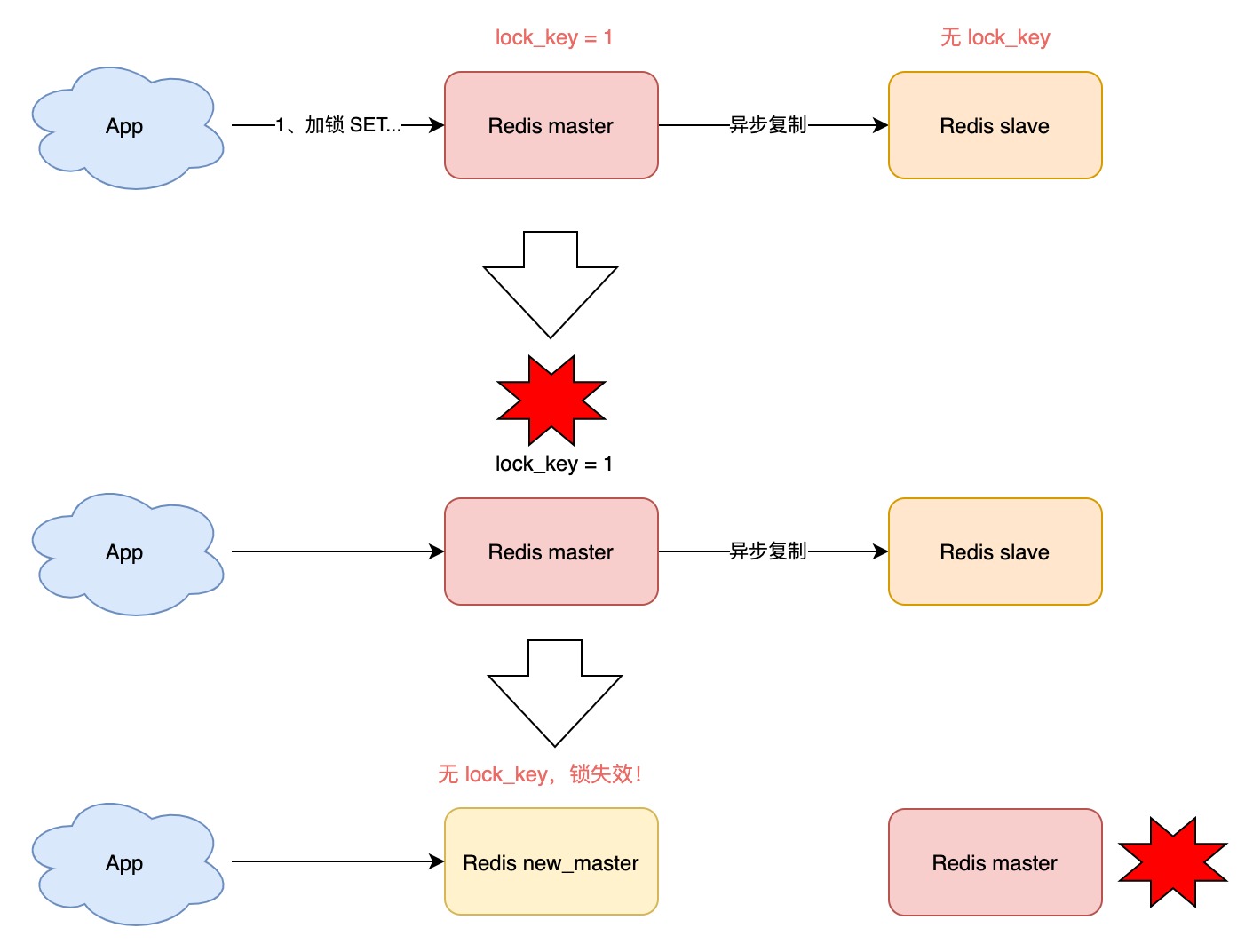
可见,当引入 Redis 副本后,分布锁还是可能会受到影响。
怎么解决这个问题?
为此,Redis 的作者提出一种解决方案,就是我们经常听到的 Redlock(红锁)。
它真的可以解决上面这个问题吗?
Redlock 真的安全吗?
好,终于到了这篇文章的重头戏。啊?上面讲的那么多问题,难道只是基础?
是的,那些只是开胃菜,真正的硬菜,从这里刚刚开始。
如果上面讲的内容,你还没有理解,我建议你重新阅读一遍,先理清整个加锁、解锁的基本流程。
如果你已经对 Redlock 有所了解,这里可以跟着我再复习一遍,如果你不了解 Redlock,没关系,我会带你重新认识它。
值得提醒你的是,后面我不仅仅是讲 Redlock 的原理,还会引出有关「分布式系统」中的很多问题,你最好跟紧我的思路,在脑中一起分析问题的答案。
现在我们来看,Redis 作者提出的 Redlock 方案,是如何解决主从切换后,锁失效问题的。
Redlock 的方案基于 2 个前提:
- 不再需要部署从库和哨兵实例,只部署主库
- 但主库要部署多个,官方推荐至少 5 个实例
也就是说,想用使用 Redlock,你至少要部署 5 个 Redis 实例,而且都是主库,它们之间没有任何关系,都是一个个孤立的实例。
注意:不是部署 Redis Cluster,就是部署 5 个简单的 Redis 实例。
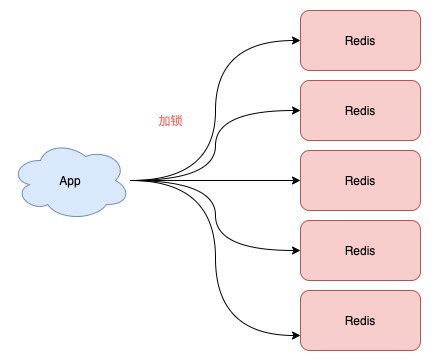
Redlock 具体如何使用呢?
整体的流程是这样的,一共分为 5 步:
整体的流程是这样的,一共分为 5 步:
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
我简单帮你总结一下,有 4 个重点:
- 客户端在多个 Redis 实例上申请加锁
- 必须保证大多数节点加锁成功
- 大多数节点加锁的总耗时,要小于锁设置的过期时间
- 释放锁,要向全部节点发起释放锁请求
第一次看可能不太容易理解,建议你把上面的文字多看几遍,加深记忆。
然后,记住这 5 步,非常重要,下面会根据这个流程,剖析各种可能导致锁失效的问题假设。
好,明白了 Redlock 的流程,我们来看 Redlock 为什么要这么做。
1) 为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
2) 为什么大多数加锁成功,才算成功?
多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。
在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。
这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。
这个问题的模型,就是我们经常听到的「拜占庭将军」问题,感兴趣可以去看算法的推演过程。
3) 为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。
所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
4) 为什么释放锁,要操作所有节点?
在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。
例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。
所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似 Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。
但事实真的如此吗?
Redlock 的争论谁对谁错?
Redis 作者把这个方案一经提出,就马上受到业界著名的分布式系统专家的质疑!
这个专家叫 Martin,是英国剑桥大学的一名分布式系统研究员。在此之前他曾是软件工程师和企业家,从事大规模数据基础设施相关的工作。它还经常在大会做演讲,写博客,写书,也是开源贡献者。
他马上写了篇文章,质疑这个 Redlock 的算法模型是有问题的,并对分布式锁的设计,提出了自己的看法。
之后,Redis 作者 Antirez 面对质疑,不甘示弱,也写了一篇文章,反驳了对方的观点,并详细剖析了 Redlock 算法模型的更多设计细节。
而且,关于这个问题的争论,在当时互联网上也引起了非常激烈的讨论。
二人思路清晰,论据充分,这是一场高手过招,也是分布式系统领域非常好的一次思想的碰撞!双方都是分布式系统领域的专家,却对同一个问题提出很多相反的论断,究竟是怎么回事?
下面我会从他们的争论文章中,提取重要的观点,整理呈现给你。
提醒:后面的信息量极大,可能不宜理解,最好放慢速度阅读。
分布式专家 Martin 对于 Relock 的质疑
在他的文章中,主要阐述了 4 个论点:
1) 分布式锁的目的是什么?
Martin 表示,你必须先清楚你在使用分布式锁的目的是什么?
他认为有两个目的。
第一,效率。
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作(例如一些昂贵的计算任务)。如果锁失效,并不会带来「恶性」的后果,例如发了 2 次邮件等,无伤大雅。
第二,正确性。
使用锁用来防止并发进程互相干扰。如果锁失效,会造成多个进程同时操作同一条数据,产生的后果是数据严重错误、永久性不一致、数据丢失等恶性问题,就像给患者服用重复剂量的药物一样,后果严重。
他认为,如果你是为了前者——效率,那么使用单机版 Redis 就可以了,即使偶尔发生锁失效(宕机、主从切换),都不会产生严重的后果。而使用 Redlock 太重了,没必要。
而如果是为了正确性,Martin 认为 Redlock 根本达不到安全性的要求,也依旧存在锁失效的问题!
2) 锁在分布式系统中会遇到的问题
Martin 表示,一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
- N:Network Delay,网络延迟
- P:Process Pause,进程暂停(GC)
- C:Clock Drift,时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC(时间比较久)
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取到了 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到了锁,发生「冲突」
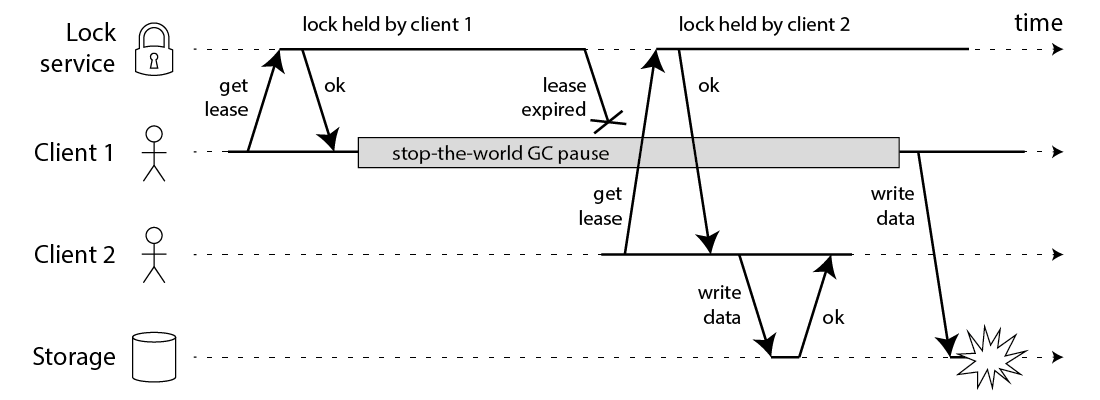
Martin 认为,GC 可能发生在程序的任意时刻,而且执行时间是不可控的。
注:当然,即使是使用没有 GC 的编程语言,在发生网络延迟、时钟漂移时,也都有可能导致 Redlock 出现问题,这里 Martin 只是拿 GC 举例。
3) 假设时钟正确的是不合理的
又或者,当多个 Redis 节点「时钟」发生问题时,也会导致 Redlock 锁失效。
- 客户端 1 获取节点 A、B、C 上的锁,但由于网络问题,无法访问 D 和 E
- 节点 C 上的时钟「向前跳跃」,导致锁到期
- 客户端 2 获取节点 C、D、E 上的锁,由于网络问题,无法访问 A 和 B
- 客户端 1 和 2 现在都相信它们持有了锁(冲突)
Martin 觉得,Redlock 必须「强依赖」多个节点的时钟是保持同步的,一旦有节点时钟发生错误,那这个算法模型就失效了。
即使 C 不是时钟跳跃,而是「崩溃后立即重启」,也会发生类似的问题。
Martin 继续阐述,机器的时钟发生错误,是很有可能发生的:
- 系统管理员「手动修改」了机器时钟
- 机器时钟在同步 NTP 时间时,发生了大的「跳跃」
总之,Martin 认为,Redlock 的算法是建立在「同步模型」基础上的,有大量资料研究表明,同步模型的假设,在分布式系统中是有问题的。
在混乱的分布式系统的中,你不能假设系统时钟就是对的,所以,你必须非常小心你的假设。
4) 提出 fencing token 的方案,保证正确性
相对应的,Martin 提出一种被叫作 fencing token 的方案,保证分布式锁的正确性。
这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个「递增」的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝「后来者」的请求
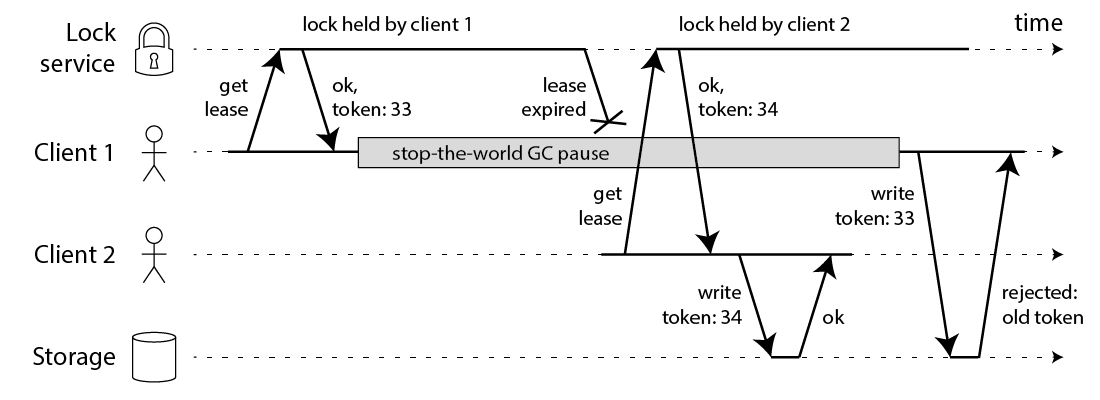
这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。
而 Redlock 无法提供类似 fencing token 的方案,所以它无法保证安全性。
他还表示,一个好的分布式锁,无论 NPC 怎么发生,可以不在规定时间内给出结果,但并不会给出一个错误的结果。也就是只会影响到锁的「性能」(或称之为活性),而不会影响它的「正确性」。
Martin 的结论:
1、Redlock 不伦不类:它对于效率来讲,Redlock 比较重,没必要这么做,而对于正确性来说,Redlock 是不够安全的。
2、时钟假设不合理:该算法对系统时钟做出了危险的假设(假设多个节点机器时钟都是一致的),如果不满足这些假设,锁就会失效。
3、无法保证正确性:Redlock 不能提供类似 fencing token 的方案,所以解决不了正确性的问题。为了正确性,请使用有「共识系统」的软件,例如 Zookeeper。
好了,以上就是 Martin 反对使用 Redlock 的观点,看起来有理有据。
下面我们来看 Redis 作者 Antirez 是如何反驳的。
Redis 作者 Antirez 的反驳
在 Redis 作者的文章中,重点有 3 个:
1) 解释时钟问题
首先,Redis 作者一眼就看穿了对方提出的最为核心的问题:时钟问题。
Redis 作者表示,Redlock 并不需要完全一致的时钟,只需要大体一致就可以了,允许有「误差」。
例如要计时 5s,但实际可能记了 4.5s,之后又记了 5.5s,有一定误差,但只要不超过「误差范围」锁失效时间即可,这种对于时钟的精度的要求并不是很高,而且这也符合现实环境。
对于对方提到的「时钟修改」问题,Redis 作者反驳到:
- 手动修改时钟:不要这么做就好了,否则你直接修改 Raft 日志,那 Raft 也会无法工作…
- 时钟跳跃:通过「恰当的运维」,保证机器时钟不会大幅度跳跃(每次通过微小的调整来完成),实际上这是可以做到的
为什么 Redis 作者优先解释时钟问题?因为在后面的反驳过程中,需要依赖这个基础做进一步解释。
2) 解释网络延迟、GC 问题
之后,Redis 作者对于对方提出的,网络延迟wan、进程 GC 可能导致 Redlock 失效的问题,也做了反驳:
我们重新回顾一下,Martin 提出的问题假设:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取节点 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到锁,发生「冲突」
Redis 作者反驳到,这个假设其实是有问题的,Redlock 是可以保证锁安全的。
这是怎么回事呢?
还记得前面介绍 Redlock 流程的那 5 步吗?这里我再拿过来让你复习一下。
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
注意,重点是 1-3,在步骤 3,加锁成功后为什么要重新获取「当前时间戳T2」?还用 T2 - T1 的时间,与锁的过期时间做比较?
Redis 作者强调:如果在 1-3 发生了网络延迟、进程 GC 等耗时长的异常情况,那在第 3 步 T2 - T1,是可以检测出来的,如果超出了锁设置的过期时间,那这时就认为加锁会失败,之后释放所有节点的锁就好了!
Redis 作者继续论述,如果对方认为,发生网络延迟、进程 GC 是在步骤 3 之后,也就是客户端确认拿到了锁,去操作共享资源的途中发生了问题,导致锁失效,那这不止是 Redlock 的问题,任何其它锁服务例如 Zookeeper,都有类似的问题,这不在讨论范畴内。
这里我举个例子解释一下这个问题:
- 客户端通过 Redlock 成功获取到锁(通过了大多数节点加锁成功、加锁耗时检查逻辑)
- 客户端开始操作共享资源,此时发生网络延迟、进程 GC 等耗时很长的情况
- 此时,锁过期自动释放
- 客户端开始操作 MySQL(此时的锁可能会被别人拿到,锁失效)
Redis 作者这里的结论就是:
- 客户端在拿到锁之前,无论经历什么耗时长问题,Redlock 都能够在第 3 步检测出来
- 客户端在拿到锁之后,发生 NPC,那 Redlock、Zookeeper 都无能为力
所以,Redis 作者认为 Redlock 在保证时钟正确的基础上,是可以保证正确性的。
3) 质疑 fencing token 机制
Redis 作者对于对方提出的 fencing token 机制,也提出了质疑,主要分为 2 个问题,这里最不宜理解,请跟紧我的思路。
第一,这个方案必须要求要操作的「共享资源服务器」有拒绝「旧 token」的能力。
例如,要操作 MySQL,从锁服务拿到一个递增数字的 token,然后客户端要带着这个 token 去改 MySQL 的某一行,这就需要利用 MySQL 的「事物隔离性」来做。
1 | // 两个客户端必须利用事物和隔离性达到目的 |
但如果操作的不是 MySQL 呢?例如向磁盘上写一个文件,或发起一个 HTTP 请求,那这个方案就无能为力了,这对要操作的资源服务器,提出了更高的要求。
也就是说,大部分要操作的资源服务器,都是没有这种互斥能力的。
再者,既然资源服务器都有了「互斥」能力,那还要分布式锁干什么?
所以,Redis 作者认为这个方案是站不住脚的。
第二,退一步讲,即使 Redlock 没有提供 fencing token 的能力,但 Redlock 已经提供了随机值(就是前面讲的 UUID),利用这个随机值,也可以达到与 fencing token 同样的效果。
如何做呢?
Redis 作者只是提到了可以完成 fencing token 类似的功能,但却没有展开相关细节,根据我查阅的资料,大概流程应该如下,如有错误,欢迎交流~
- 客户端使用 Redlock 拿到锁
- 客户端在操作共享资源之前,先把这个锁的 VALUE,在要操作的共享资源上做标记
- 客户端处理业务逻辑,最后,在修改共享资源时,判断这个标记是否与之前一样,一样才修改(类似 CAS 的思路)
还是以 MySQL 为例,举个例子就是这样的:
- 客户端使用 Redlock 拿到锁
- 客户端要修改 MySQL 表中的某一行数据之前,先把锁的 VALUE 更新到这一行的某个字段中(这里假设为 current_token 字段)
- 客户端处理业务逻辑
- 客户端修改 MySQL 的这一行数据,把 VALUE 当做 WHERE 条件,再修改
1 | UPDATE table T SET val = $new_val WHERE id = $id AND current_token = $redlock_value |
可见,这种方案依赖 MySQL 的事物机制,也达到对方提到的 fencing token 一样的效果。
但这里还有个小问题,是网友参与问题讨论时提出的:两个客户端通过这种方案,先「标记」再「检查+修改」共享资源,那这两个客户端的操作顺序无法保证啊?
而用 Martin 提到的 fencing token,因为这个 token 是单调递增的数字,资源服务器可以拒绝小的 token 请求,保证了操作的「顺序性」!
Redis 作者对于这个问题做了不同的解释,我觉得很有道理,他解释道:分布式锁的本质,是为了「互斥」,只要能保证两个客户端在并发时,一个成功,一个失败就好了,不需要关心「顺序性」。
前面 Martin 的质疑中,一直很关心这个顺序性问题,但 Redis 的作者的看法却不同。
综上,Redis 作者的结论:
1、作者同意对方关于「时钟跳跃」对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。
2、Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
是不是觉得很有意思?
在分布式系统中,一个小小的锁,居然可能会遇到这么多问题场景,影响它的安全性!
不知道你看完双方的观点,更赞同哪一方的说法呢?
别急,后面我还会综合以上论点,谈谈自己的理解。
好,讲完了双方对于 Redis 分布锁的争论,你可能也注意到了,Martin 在他的文章中,推荐使用 Zookeeper 实现分布式锁,认为它更安全,确实如此吗?
基于 Zookeeper 的锁安全吗?
如果你有了解过 Zookeeper,基于它实现的分布式锁是这样的:
- 客户端 1 和 2 都尝试创建「临时节点」,例如 /lock
- 假设客户端 1 先到达,则加锁成功,客户端 2 加锁失败
- 客户端 1 操作共享资源
- 客户端 1 删除 /lock 节点,释放锁
你应该也看到了,Zookeeper 不像 Redis 那样,需要考虑锁的过期时间问题,它是采用了「临时节点」,保证客户端 1 拿到锁后,只要连接不断,就可以一直持有锁。
而且,如果客户端 1 异常崩溃了,那么这个临时节点会自动删除,保证了锁一定会被释放。
不错,没有锁过期的烦恼,还能在异常时自动释放锁,是不是觉得很完美?
其实不然。
思考一下,客户端 1 创建临时节点后,Zookeeper 是如何保证让这个客户端一直持有锁呢?
原因就在于,客户端 1 此时会与 Zookeeper 服务器维护一个 Session,这个 Session 会依赖客户端「定时心跳」来维持连接。
如果 Zookeeper 长时间收不到客户端的心跳,就认为这个 Session 过期了,也会把这个临时节点删除。
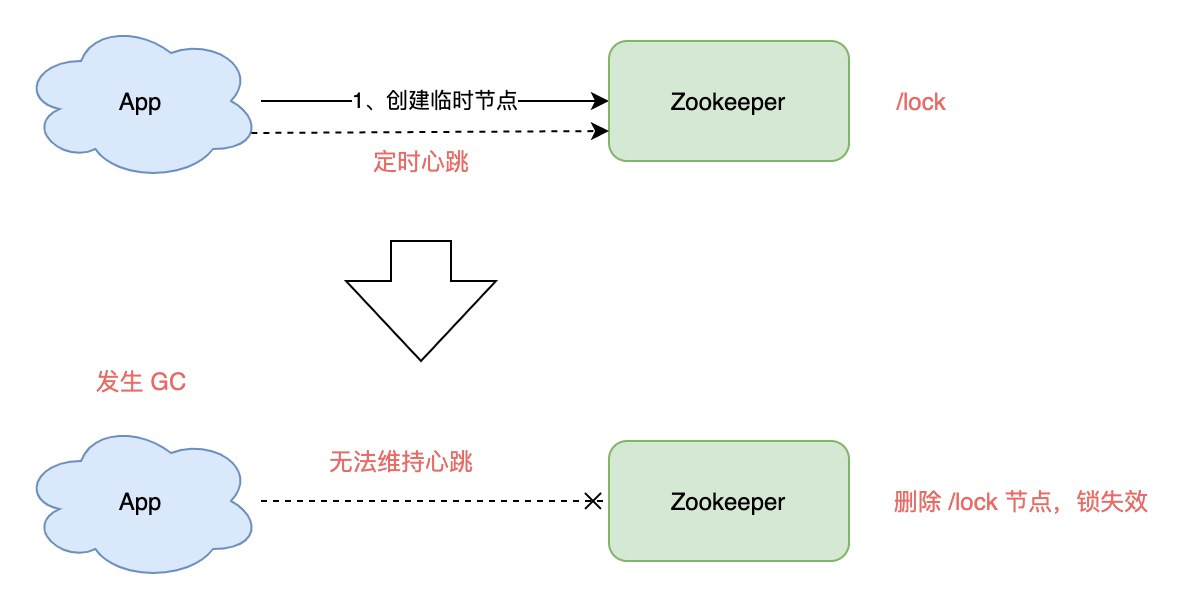
同样地,基于此问题,我们也讨论一下 GC 问题对 Zookeeper 的锁有何影响:
- 客户端 1 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 发生长时间 GC
- 客户端 1 无法给 Zookeeper 发送心跳,Zookeeper 把临时节点「删除」
- 客户端 2 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 GC 结束,它仍然认为自己持有锁(冲突)
可见,即使是使用 Zookeeper,也无法保证进程 GC、网络延迟异常场景下的安全性。
这就是前面 Redis 作者在反驳的文章中提到的:如果客户端已经拿到了锁,但客户端与锁服务器发生「失联」(例如 GC),那不止 Redlock 有问题,其它锁服务都有类似的问题,Zookeeper 也是一样!
所以,这里我们就能得出结论了:一个分布式锁,在极端情况下,不一定是安全的。
如果你的业务数据非常敏感,在使用分布式锁时,一定要注意这个问题,不能假设分布式锁 100% 安全。
好,现在我们来总结一下 Zookeeper 在使用分布式锁时优劣:
Zookeeper 的优点:
- 不需要考虑锁的过期时间
- watch 机制,加锁失败,可以 watch 等待锁释放,实现乐观锁
但它的劣势是:
- 性能不如 Redis
- 部署和运维成本高
- 客户端与 Zookeeper 的长时间失联,锁被释放问题
对分布式锁的理解
好了,前面详细介绍了基于 Redis 的 Redlock 和 Zookeeper 实现的分布锁,在各种异常情况下的安全性问题,下面我想和你聊一聊我的看法,仅供参考,不喜勿喷。
1) 到底要不要用 Redlock?
前面也分析了,Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。
但保证时钟正确,我认为并不是你想的那么简单就能做到的。
第一,从硬件角度来说,时钟发生偏移是时有发生,无法避免的。
例如,CPU 温度、机器负载、芯片材料都是有可能导致时钟发生偏移。
第二,从我的工作经历来说,曾经就遇到过时钟错误、运维暴力修改时钟的情况发生,进而影响了系统的正确性,所以,人为错误也是很难完全避免的。
所以,我对 Redlock 的个人看法是,尽量不用它,而且它的性能不如单机版 Redis,部署成本也高,我还是会优先考虑使用 Redis「主从+哨兵」的模式,实现分布式锁。
那正确性如何保证呢?第二点给你答案。
2) 如何正确使用分布式锁?
在分析 Martin 观点时,它提到了 fencing token 的方案,给我了很大的启发,虽然这种方案有很大的局限性,但对于保证「正确性」的场景,是一个非常好的思路。
所以,我们可以把这两者结合起来用:
1、使用分布式锁,在上层完成「互斥」目的,虽然极端情况下锁会失效,但它可以最大程度把并发请求阻挡在最上层,减轻操作资源层的压力。
2、但对于要求数据绝对正确的业务,在资源层一定要做好「兜底」,设计思路可以借鉴 fencing token 的方案来做。
两种思路结合,我认为对于大多数业务场景,已经可以满足要求了。
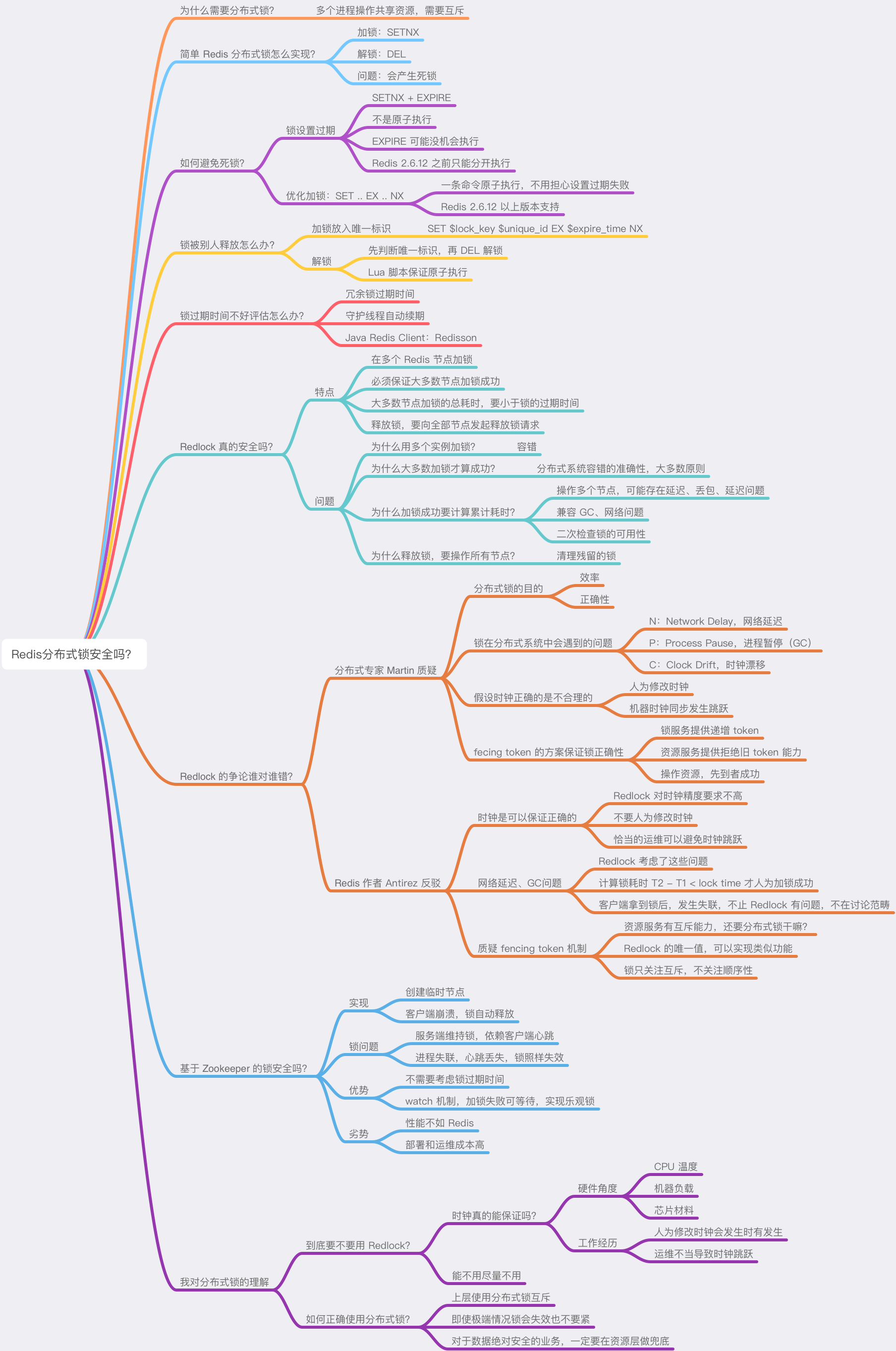
附上脑图:
数据库和缓存保证一致性
说到数据库和缓存的读写顺序,最经典的方案就是这个所谓的 Cache Aside Pattern 了。其实这个方案一点也不高大上,基本上我们平时都在用,只是未必知道名字而已,下面简单介绍一下这个方案的思路:
- 失效:程序先从缓存中读取数据,如果没有命中,则从数据库中读取,成功之后将数据放到缓存中
- 命中:程序先从缓存中读取数据,如果命中,则直接返回
- 更新:程序先更新数据库,在删除缓存
前两步跟数据读取顺序有关,我觉得大家对这样的设计应该都没有异议。读数据的时候当然要优先从缓存中读取,读不到当然要从数据库中读取,然后还要放到缓存中,否则下次请求过来还得从数据库中读取。关键问题在于第三点,也就是数据更新流程,为什么要先更新数据库?为什么之后要删除缓存而不是更新?这就是本文主要要讨论的问题。
总共大概有四种可能的选项(你不可能把数据库删了吧…):
- 先更新缓存,再更新数据库
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
接下来我们分情况逐个讨论一下
先更新缓存,再更新数据库
我们都知道不管是操作数据库还是操作缓存,都有失败的可能。如果我们先更新缓存,再更新数据库,假设更新数据库失败了,那数据库中就存的是老数据。当然你可以选择重试更新数据库,那么再极端点,负责更新数据库的机器也宕机了,那么数据库中的数据将一直得不到更新,并且当缓存失效之后,其他机器再从数据库中读到的数据是老数据,然后再放到缓存中,这就导致先前的更新操作被丢失了,因此这么做的隐患是很大的。
从数据持久化的角度来说,数据库当然要比缓存做的好,我们也应当以数据库中的数据为主,所以需要更新数据的时候我们应当首先更新数据库,而不是缓存。
先更新数据库,再更新缓存
这里主要有两个问题,首先是并发的问题:假设线程 A(或者机器 A,道理是一样的)和线程 B 需要更新同一个数据,A 先于 B 但时间间隔很短,那么就有可能会出现:
- 线程 A 更新了数据库
- 线程 B 更新了数据库
- 线程 B 更新了缓存
- 线程 A 更新了缓存
按理说线程 B 应该最后更新缓存,但是可能因为网络等原因,导致线程 B 先于线程 A 对缓存进行了更新,这就导致缓存中的数据不是最新的。
第二个问题是,我们不确定要更新的这个缓存项是否会被经常读取,假设每次更新数据库都会导致缓存的更新,有可能数据还没有被读取过就已经再次更新了,这就造成了缓存空间的浪费。另外,缓存中的值可能是经过一系列计算的,而并不是直接跟数据库中的数据对应的,频繁更新缓存会导致大量无效的计算,造成机器性能的浪费。
综上所述,更新缓存这一方案是不可取的,我们应当考虑删除缓存。
先删除缓存,再更新数据库
这个方案的问题也是很明显的,假设现在有两个请求,一个是写请求 A,一个是读请求 B,那么可能出现如下的执行序列:
- 请求 A 删除缓存
- 请求 B 读取缓存,发现不存在,从数据库中读取到旧值
- 请求 A 将新值写入数据库
- 请求 B 将旧值写入缓存
这样就会导致缓存中存的还是旧值,在缓存过期之前都无法读到新值。这个问题在数据库读写分离的情况下会更明显,因为主从同步需要时间,请求 B 获取到的数据很可能还是旧值,那么写入缓存中的也会是旧值。
先更新数据库,再删除缓存
终于来到我们最常用的方案了,但是最常用并不是说就一定不会有任何问题,我们依然假设有两个请求,请求 A 是查询请求,请求 B 是更新请求,那么可能会出现下述情形:
- 先前缓存刚好失效
- 请求 A 查数据库,得到旧值
- 请求 B 更新数据库
- 请求 B 删除缓存
- 请求 A 将旧值写入缓存
上述情况确实有可能出现,但是出现的概率可能不高,因为上述情形成立的条件是在读取数据时,缓存刚好失效,并且此时正好又有一个并发的写请求。考虑到数据库上的写操作一般都会比读操作要慢,(这里指的是在写数据库时,数据库一般都会上锁,而普通的查询语句是不会上锁的。当然,复杂的查询语句除外,但是这种语句的占比不会太高)并且联系常见的数据库读写分离的架构,可以合理认为在现实生活中,读请求的比例要远高于写请求,因此我们可以得出结论。这种情况下缓存中存在脏数据的可能性是不高的。
那如果是读写分离的场景下呢?如果按照如下所述的执行序列,一样会出问题:
- 请求 A 更新主库
- 请求 A 删除缓存
- 请求 B 查询缓存,没有命中,查询从库得到旧值
- 从库同步完毕
- 请求 B 将旧值写入缓存
如果数据库主从同步比较慢的话,同样会出现数据不一致的问题。事实上就是如此,毕竟我们操作的是两个系统,在高并发的场景下,我们很难去保证多个请求之间的执行顺序,或者就算做到了,也可能会在性能上付出极大的代价。那为什么我们还是应当采用先更新数据库,再删除缓存这个策略呢?首先,为什么要删除而不是更新缓存,这个在前面有分析,这里不再赘述。那为什么我们应当先更新数据库呢?因为缓存在数据持久化这方面往往没有数据库做得好,而且数据库中的数据是不存在过期这个概念的,我们应当以数据库中的数据为主,缓存因为有着过期时间这一概念,最终一定会跟数据库保持一致。
那如果我就是想解决上述说的这两个问题,在不要求强一致性的情况下可以怎么做呢?
有没有更好的思路?
其实在讨论最后一个方案时,我们没有考虑操作数据库或者操作缓存可能失败的情况,而这种情况也是客观存在的。那么在这里我们简单讨论下,首先是如果更新数据库失败了,其实没有太大关系,因为此时数据库和缓存中都还是老数据,不存在不一致的问题。假设删除缓存失败了呢?此时确实会存在数据不一致的情况。除了设置缓存过期时间这种兜底方案之外,如果我们希望尽可能保证缓存可以被及时删除,那么我们必须要考虑对删除操作进行重试。
删除重试
你当然可以直接在代码中对删除操作进行重试,但是要知道如果是网络原因导致的失败,立刻进行重试操作很可能也是失败的,因此在每次重试之间你可能需要等待一段时间,比如几百毫秒甚至是秒级等待。为了不影响主流程的正常运行,你可能会将这个事情交给一个异步线程或者线程池来执行,但是如果机器此时也宕机了,这个删除操作也就丢失了。
引入 MQ
那要怎么解决这个问题呢?首先可以考虑引入消息队列,OK我知道写入消息队列一样可能会失败,但是这是建立在缓存跟消息队列都不可用的情况下,应该说这样的概率是不高的。引入消息队列之后,就由消费端负责删除缓存以及重试,可能会慢一些但是可以保证操作不会丢失。
回到上述的两个问题中去,上述的两个问题的核心其实都在于将旧值写入了缓存,那么解决这个问题的办法其实就是要将缓存删除,考虑到网络问题导致的执行失败或执行顺序的问题,这里要进行的删除操作应当是异步延时操作。具体来说应该怎么做呢?就是参考前面说的,引入消息队列,在删除缓存失败的情况下,将删除缓存作为一条消息写入消息队列,然后由消费端进行慢慢的消费和重试。
引入 canel
那如果是读写分离场景呢?我们知道数据库(以 Mysql 为例)主从之间的数据同步是通过 binlog 同步来实现的,因此这里可以考虑订阅 binlog(可以使用 canal 之类的中间件实现),提取出要删除的缓存项,然后作为消息写入消息队列,然后再由消费端进行慢慢的消费和重试。在这种情况下,程序可以不去主动删除缓存,但如果你希望缓存中尽快读取到最新的值,也可以考虑将缓存删除,那么就有可能出现又将旧值写入缓存,且缓存被重复删除的情况。但是一般来说这不会是个问题,首先旧值重新写入缓存,情况无非就是又退化到了程序没有主动删除缓存的这一情况,另外,重复删除缓存保证了数据库和缓存之间不会存在长时间的数据不一致。(为什么删除了缓存之后,还是有可能将旧值写入缓存?参见上面先更新数据库,再删除缓存的方案下,读写分离场景下的执行序列)当然我个人的建议是,如果你可以忍受一段时间之内的数据不一致,那就没必要自己再主动去删除缓存了。
要解决上述问题的核心就在于要实现异步延时删除这一策略,因此在这里我们需要引入消息队列。如果数据库采用读写分离架构,则需要考虑订阅 binlog ,否则一样可能会出现先删除,后同步完毕的情况。
缓存击穿
可能会有同学注意到,如果采用删除缓存的方案,在高并发场景下可能会导致缓存击穿(这个跟缓存穿透还有点区别),也就是大量的请求同时去查询同一个缓存,但是这个缓存又刚好过期或者被删除了,那么所有的请求全部都会打到数据库上,导致严重的性能问题。对于这个问题包括如何解决缓存穿透,后面我可能会考虑单独写文章来阐释一下,这里先简单说下解决思路,其实也就是上锁。
分布式锁
当一个线程需要去访问这个缓存的时候,如果发现缓存为空,则需要先去竞争一个锁,如果成功则进行正常的数据库读取和写入缓存这一操作,然后再释放锁,否则就等待一段时间之后,重新尝试读取缓存,如果还没有数据就继续去竞争锁。这个是单机场景,如果有多台机器同时去访问同一个缓存项该怎么办呢?如果机器数不是很多的话,这种情况一般来说也不会成为一个问题,不过这里有个优化点,就是从数据库读取到数据之后,再对缓存做一次判断,如果缓存中已经存在数据,就不需要再写一遍缓存了。但是如果机器数也很多的话,那么就得考虑上分布式锁了。此方案的问题是显而易见的,加锁尤其是加分布式锁会对系统性能有重大影响,而且分布式锁的实现非常考验开发者的经验和实力,在高并发场景下这一点显得尤为重要,因此我建议各位,不到万不得已的情况下,不要盲目上分布式锁。
怎么做到强一致性?
可能有同学就是要来抬杠,现有的这些方案还是不够完美,如果我就是想要做到强一致性可以怎么做?
上一致性协议当然是可以的,虽然成本也是非常客观的。2PC 甚至是 3PC 本身是存在一定程度的缺陷的,所以如果要采用这个方案,那么在架构设计中要引入很多的容错,回退和兜底措施。那如果是上 Paxos 和 Raft 呢?那么你首先至少要看过这两者的相关论文,并且调研清楚目前市面上有哪些开源方案,并做好充分的验证,并且能够做到出了问题自己有能力修复…对了,我还没提到性能问题呢。
那除了一致性协议以外,有没有其他的思路?
我们先回到”先更新数据库,再删除缓存”这个方案本身上来,从字面上来看,这里有两步操作,因此在数据库更新之前,到缓存被删除这段时间之内,读请求读取到的都是脏数据。如果要实现这两者的强一致性,只能是在更新完数据库之前,所有的读请求都必须要被阻塞直到缓存最终被删除为止。如果是读写分离的场景,则要在更新完主库之前就开始阻塞读请求,直到主从同步完毕,且缓存被删除之后才能释放。
这个思路其实就是一种串行化的思路,写请求一定要在读请求之前完成,才能保证最新的数据对所有读请求来说是可见的。说到这里是不是让你想起了什么?比如 volatile,内存屏障,ReadWriteLock,或者是数据库的共享锁,排他锁…当前场景可能不同,但是要面对的问题都是相似的。
现在回到问题本身,我们要怎么实现这种阻塞呢?可能有同学已经发现了,我们需要的其实是一种 分布式读写锁。对于写请求来说,在更新数据库之前,必须要先申请写锁,而其他线程或机器在读取数据之前,必须要先申请读锁。读锁是共享的,写锁是排他的,即如果读锁存在,可以继续申请读锁但无法申请写锁,如果写锁存在,则无论是读锁还是写锁都无法申请。只有实现了这种分布式读写锁,才能保证写请求在完成数据库和缓存的操作之前,读请求不会读取到脏数据。
注意,这里用到的分布式读写锁并没有解决缓存击穿的问题,因为从读请求的视角来看,如果发生了更新数据库的情况,读请求要么被阻塞,要么就是缓存为空,需要从数据库读取数据再写入缓存。为了防止因缓存失效或被删除导致大量请求直接打到数据库上导致数据库崩溃,你只能考虑加锁甚至是加分布式锁,具体参见缓存击穿这一章节。
那么说到分布式读写锁,其实现一样有一定的难度。如果确定要使用,我建议使用Curator提供的 InterProcessReadWriteLock,或者是 Redisson 提供的 RReadWriteLock。对分布式读写锁的讨论超出了本文的范围,这里就不做过多展开了。
总结
在我看来所谓的架构设计,往往是要在众多的 trade-off 中选择最适合当前场景的。其实一旦在方案中使用了缓存,那往往也就意味着我们放弃了数据的强一致性,但这也意味着我们的系统在性能上能够得到一些提升。在如何使用缓存这个问题上有很多的讲究,比如过期时间的合理设置,怎么解决或规避缓存穿透,击穿甚至是雪崩的问题。后续有机会的话,我会逐步地阐释清楚这些问题的来龙去脉,以及如何去解决比较合适。
扩展/相关阅读
- 阿里云 Redis 开发规范 - https://www.infoq.cn/article/K7dB5AFKI9mr5Ugbs_px
- 为什么要防止 bigkey? - https://mp.weixin.qq.com/s?__biz=Mzg2NTEyNzE0OA==&mid=2247483677&idx=1&sn=5c320b46f0e06ce9369a29909d62b401&chksm=ce5f9e9ef928178834021b6f9b939550ac400abae5c31e1933bafca2f16b23d028cc51813aec&scene=21#wechat_redirect
- Redis【入门】就这一篇! - https://www.wmyskxz.com/2018/05/31/redis-ru-men-jiu-zhe-yi-pian/
- Linux I/O 原理和 Zero-copy 技术全面揭秘 - https://strikefreedom.top/linux-io-and-zero-copy
- Go netpoller 原生网络模型之源码全面揭秘 - https://strikefreedom.top/go-netpoll-io-multiplexing-reactor
参考资料
- 《Redis 设计与实现》 - http://redisbook.com/
- 【官方文档】Redis 数据类型介绍 - http://www.redis.cn/topics/data-types-intro.html
- 《Redis 深度历险》 - https://book.douban.com/subject/30386804/
- 阿里云 Redis 开发规范 - https://www.infoq.cn/article/K7dB5AFKI9mr5Ugbs_px
- Redis 快速入门 - 易百教程 - https://www.yiibai.com/redis/redis_quick_guide.html
- Redis【入门】就这一篇! - https://www.wmyskxz.com/2018/05/31/redis-ru-men-jiu-zhe-yi-pian/
- 数据结构–跳跃表 - https://www.cnblogs.com/hunternet/p/11248192.html
- Redis 的三种集群模式 - https://segmentfault.com/a/1190000022808576
- Redis 事务和 watch - https://www.jianshu.com/p/361cb9cd13d5
- Spring 整合 Redis - https://segmentfault.com/a/1190000022152037
- 深度剖析:Redis分布式锁到底安全吗 - http://kaito-kidd.com/2021/06/08/is-redis-distributed-lock-really-safe/
- 颠覆认知——Redis会遇到的15个「坑」 - http://kaito-kidd.com/2021/03/14/redis-trap/
- 聊聊数据库与缓存数据一致性问题 - https://juejin.cn/post/6844903941646319623
- Redis 多线程全揭秘 - https://segmentfault.com/a/1190000039223696




