Jsoup
官网 :https://jsoup.org 介绍如下:
jsoup实现WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
- 从URL,文件或字符串中刮取和解析 HTML
- 使用DOM遍历或CSS选择器查找和提取数据
- 操纵 HTML元素,属性和文本
- 清除用户提交的内容以防止安全白名单,以防止XSS攻击
- 输出整洁的HTML
SpringBoot 集成
依赖
1
2
3
4
5
| <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
|
过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Configuration;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@WebFilter(filterName = "xssFilter", urlPatterns = {"*.json"})
@Slf4j
@Configuration
public class XssRequestFilter implements Filter {
private static List<String> MATCH_WORD = new ArrayList<>();
static {
MATCH_WORD.add("SAVE");
MATCH_WORD.add("UPDATE");
MATCH_WORD.add("INSERT");
MATCH_WORD.add("SET");
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
if (request instanceof HttpServletRequest){
HttpServletRequest hsr = (HttpServletRequest) request;
String s = hsr.getRequestURL().toString().toUpperCase();
boolean b = MATCH_WORD.stream().anyMatch(w -> s.contains(w));
if (b){
request = new XssHttpServletRequestWrapper((HttpServletRequest) request);
}
}
filterChain.doFilter(request, response);
}
@Override
public void destroy() {
}
}
|
因为这里我不想所有请求都经过xss过滤处理, 所以就把请求路径中,含有”save”,“update”,“set”,”insert”的这些入库保存的一些接口来进行过滤
wrapper 包装类
写的这个Filter过滤类, 目的就是为了将原生的HttpServletRequest, 包装成我们自己的XssRequest,这样我们在web层获取参数的时候,都是从包装的reqeust中获取加工后的参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
| import com.zgd.common.util.JsoupUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.ArrayUtils;
import javax.servlet.ReadListener;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.*;
import java.nio.charset.Charset;
import java.util.stream.Stream;
@Slf4j
public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper {
private HttpServletRequest orgRequest = null;
boolean isUpData = false;
public XssHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
orgRequest = request;
String contentType = request.getContentType();
if (null != contentType) {
isUpData = contentType.startsWith("multipart");
}
}
@Override
public String getParameter(String name) {
String value = super.getParameter(name);
if (value != null) {
value = JsoupUtil.clean(value);
}
return value;
}
@Override
public String[] getParameterValues(String name) {
String[] values = super.getParameterValues(name);
if (ArrayUtils.isNotEmpty(values)) {
values = Stream.of(values).map(s -> JsoupUtil.clean(name)).toArray(String[]::new);
}
return values;
}
@Override
public String getHeader(String name) {
String value = super.getHeader(name);
if (value != null) {
value = JsoupUtil.clean(value);
}
return value;
}
@Override
public ServletInputStream getInputStream() throws IOException {
if (isUpData) {
return super.getInputStream();
} else {
byte[] bytes = inputHandlers(super.getInputStream()).getBytes();
final ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
return new ServletInputStream() {
@Override
public int read() throws IOException {
return bais.read();
}
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
};
}
}
public String inputHandlers(ServletInputStream servletInputStream) {
StringBuilder sb = new StringBuilder();
BufferedReader reader = null;
try {
reader = new BufferedReader(new InputStreamReader(servletInputStream, Charset.forName("UTF-8")));
String line = "";
while ((line = reader.readLine()) != null) {
sb.append(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (servletInputStream != null) {
try {
servletInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
String finl = JsoupUtil.cleanJson(sb.toString());
return finl;
}
}
|
在这个wrapper包装类中,我对一些常用的获取参数的方法都进行了重写. 使用JsoupUtil.clean(value)进行了处理,这个JsoupUtil就是的重点
JsoupUtil
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.safety.Whitelist;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Slf4j
public class JsoupUtil{
static Whitelist WHITELIST = Whitelist.relaxed();
static Document.OutputSettings OUTPUT_SETTINGS = new Document.OutputSettings().prettyPrint(false);
static {
WHITELIST.addAttributes(":all","style");
WHITELIST.preserveRelativeLinks(true);
}
public static String clean(String s) {
log.info("[xss过滤标签和属性] [原字符串为] : {}",s);
String r = Jsoup.clean(s, "http://base.uri", WHITELIST, OUTPUT_SETTINGS);
log.info("[xss过滤标签和属性] [过滤后的字符串为] : {}",r);
return r;
}
public static String cleanJson(String s) {
s = jsonStringConvert(s);
return clean(s);
}
public static String jsonStringConvert(String s) {
log.info("[处理JSON字符串] [将嵌套的双引号转成单引号] [原JSON] :{}",s);
char[] temp = s.toCharArray();
int n = temp.length;
for (int i = 0; i < n; i++) {
if (temp[i] == ':' && temp[i + 1] == '"') {
for (int j = i + 2; j < n; j++) {
if (temp[j] == '"') {
if (temp[j + 1] != ',' && temp[j + 1] != '}') {
temp[j] = '\'';
} else if (temp[j + 1] == ',' || temp[j + 1] == '}') {
break;
}
}
}
}
}
String r = new String(temp);
log.info("[处理JSON字符串] [将嵌套的双引号转成单引号] [处理后的JSON] :{}",r);
return r;
}
public static void main(String[] args) {
String s = "<p><a href=\"www.test.xhtml\">test</a><a title=\"哈哈哈\" href=\"/aaaa.bbv.com\" href1=\"www.baidu.com\" href2=\"www.baidu.com\" onclick=\"click()\"></a><script>ss</script><img script=\"xxx\" " +
"onclick=function src=\"https://www.xxx.png\" title=\"\" width=\"100%\" alt=\"\"/>" +
"<br/></p><p>电饭锅进口量的说法</p><p>————————</p><p><span style=\"text-decoration: line-through;\">大幅度发</span></p>" +
"<p><em>sd</em></p><p><em><span style=\"text-decoration: underline;\">dsf</span></em></p><p><em>" +
"<span style=\"border: 1px solid rgb(0, 0, 0);\">撒地方</span></em></p><p><span style=\"color: rgb(255, 0, 0);\">似懂非懂</span><br/></p>" +
"<p><span style=\"color: rgb(255, 0, 0);\"><strong>撒地方</strong></span></p><p><span style=\"color: rgb(221, 217, 195);\"><br/></span></p>" +
"<p style=\"text-align: center;\"><span style=\"color: rgb(0, 0, 0); font-size: 20px;\">撒旦法</span></p><p><br/></p>";
System.out.println(clean(s));
}
}
|
首先Whitelist.relaxed()是指标签的白名单, 在这个白名单外的其他标签将会被替换为空字符串
除了Whitelist.relaxed(),还有下面几种预设的可以选择.官网Whitelist介绍

- Whitelist.none()
仅允许文本节点:将剥离所有HTML。
- Whitelist.basic()
允许a, b, blockquote, br, cite, code, dd, dl, dt, em, i, li, ol, p, pre, q, small, span, strike, strong, sub, sup, u, ul和适当的属性
- Whitelist.simpleText()
此白名单只允许简单的文本格式: b, em, i, strong, u。
- Whitelist.basicWithImages()
此白名单允许使用相应的文本标签Whitelist.basic(),并且还允许 img带有适当属性的标签 src指向 http或 https。
除了上面的预设,我们还可以自己添加白名单标签:
1
2
|
public Whitelist addTags(String ... tags)
|
添加白名单属性
1
2
| public Whitelist addAttributes(String tag,String ... attributes)
|
5. 测试xss攻击
1
2
| String l = "<p><javascript>alert(2);</javascript><img SRC=javascript:alert('XSS')/><img SRC=http://3w.org/XSS/xss.js/><script SRC=http://3w.org/XSS/xss.js>alert(2)</script><a href=\"http:/www.sss.js\" onclick=function() >test</a>";
System.out.println(clean(l));
|
结果:
1
| <p>alert(2);<img><img><a href="http:/www.sss.js">test</a></p>
|
Jsoup的几个坑
1. Jsoup会对不在白名单的标签进行删除处理, 而且如果标签没有闭合, 会将这个标签一直删除到闭合为止
1
2
| String l = "<p是事实上事实上事实 <span>span标签</span><h1>一级标题</h1>";
System.out.println(clean(l));
|
返回结果 (将不匹配的</span>也去掉了)
这个问题在json请求中格外严重
1
2
| String l = "{\"name\":\"zgd<p\",\"desc\":\"是事实上事实上事实 <span>span标签</span><h1>一级标题</h1>\"}";
System.out.println(clean(l));
|
结果: 已经完全错误了
1
| {"name":"zgdspan标签<h1>一级标题</h1>"}
|
2. Jsoup处理后,富文本内容中图片和a标签的href属性丢失
比如我们处理:
1
2
| String l = "<p><a href=\"www.test.xhtml\">test</a>";
System.out.println(clean(l));
|
结果却是:
就算加上whitelist.addAttributes("a","href")也无济于事
最后发现了这个:
1
| whitelist.preserveRelativeLinks(true);
|
public Whitelist preserveRelativeLinks(boolean preserve)
是否保留元素的URL属性中的相对链接,或将它们转换为绝对链接,默认为false. 为false时将会把baseUri和元素的URL属性拼接起来
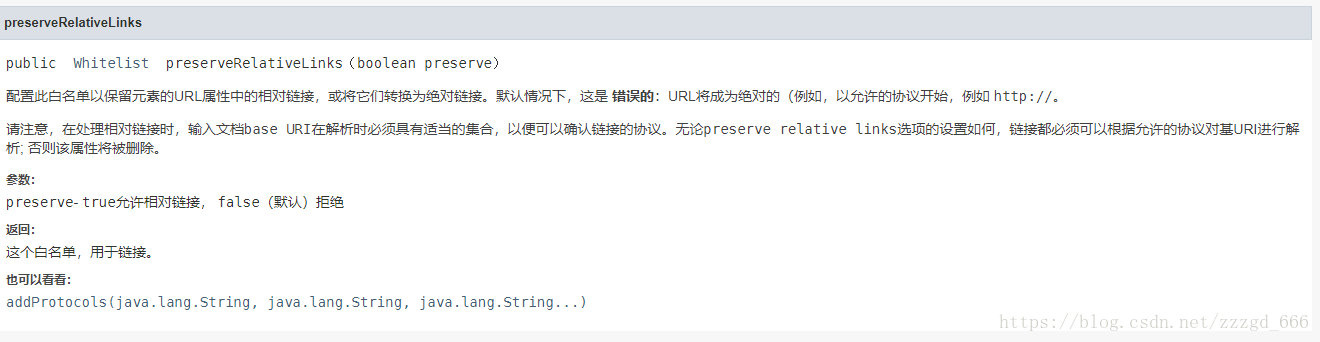
baseUri也就是api中的
1
| static String clean(String bodyHtml, String baseUri, Whitelist whitelist, Document.OutputSettings outputSettings)
|
代码:
1
2
|
String r = Jsoup.clean(s, "http://base.uri", WHITELIST, OUTPUT_SETTINGS);
|
如果baseUri为空字符串或者不符合Http://xx类似的协议开头,属性中的URL链接将会被删除,如<a href='xxx'/>会变成<a/>
如果WHITELIST.preserveRelativeLinks(false), 会将baseUri和属性中的URL链接进行拼接
测试几种情况:
1
2
| String l = "<p><a href=\"www.test.xhtml\">test</a><a href=\"/abc.com\">ttt</a><a href=\"http://www.test.xhtml\">ggg</a>";
System.out.println(clean(l));
|
- baseUri = “”, preserveRelativeLinks(false)
结果:
1
| <p><a>test</a><a>ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
- baseUri = “”, preserveRelativeLinks(true)
结果:
1
| <p><a>test</a><a>ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
- baseUri = “xxx”, preserveRelativeLinks(true)
结果:
1
| <p><a>test</a><a>ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
- baseUri = “xxx”, preserveRelativeLinks(false)
结果:
1
| <p><a>test</a><a>ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
结果:
1
| <p><a href="http://base.uri/www.test.xhtml">test</a><a href="http://base.uri/abc.com">ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
结果:
1
| <p><a href="www.test.xhtml">test</a><a href="/abc.com">ttt</a><a href="http://www.test.xhtml">ggg</a></p>
|
总结:
- 标签中的URL链接, 以白名单中的协议名(
http:// , https://…)开头的时候, 永远都存在
- 标签中的URL链接不满足白名单中的协议名(
http:// , https://…)开头的时候:
- baseUri不满足
http://xxx和https://等协议名开头的时候, 不管preserveRelativeLinks设置true还是false, 都会删除href属性
- 当baseUri满足协议名开头的时候, preserveRelativeLinks为true的时候, 保留href不作处理 , 为false的时候会拼接参数
综上所述, 设置一个类似http://base.uri的baseUri, preserveRelativeLinks设置为true就可以保证所有URL不会删除





